大数据成神之路-Java高级特性增强(ConcurrentSkipListMap)
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了大数据成神之路-Java高级特性增强(ConcurrentSkipListMap),小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含18396字,纯文字阅读大概需要27分钟。
内容图文
")
导语
本节课是Java.util.concurrent包中的ConcurrentSkipListMap类。
1概要
本章对Java.util.concurrent包中的ConcurrentSkipListMap类进行详细的介绍。内容包括:
ConcurrentSkipListMap介绍
ConcurrentSkipListMap原理和数据结构
ConcurrentSkipListMap函数列表
ConcurrentSkipListMap源码分析
ConcurrentSkipListMap示例
2ConcurrentSkipListMap介绍
ConcurrentSkipListMap是线程安全的有序的哈希表,适用于高并发的场景。
ConcurrentSkipListMap和TreeMap,它们虽然都是有序的哈希表。但是,第一,它们的线程安全机制不同,TreeMap是非线程安全的,而ConcurrentSkipListMap是线程安全的。
第二,ConcurrentSkipListMap是通过跳表实现的,而TreeMap是通过红黑树实现的。
关于跳表(Skip List),它是平衡树的一种替代的数据结构,但是和红黑树不相同的是,跳表对于树的平衡的实现是基于一种随机化的算法的,这样也就是说跳表的插入和删除的工作是比较简单的。
3ConcurrentSkipListMap原理和数据结构
ConcurrentSkipListMap的数据结构,如下图所示:
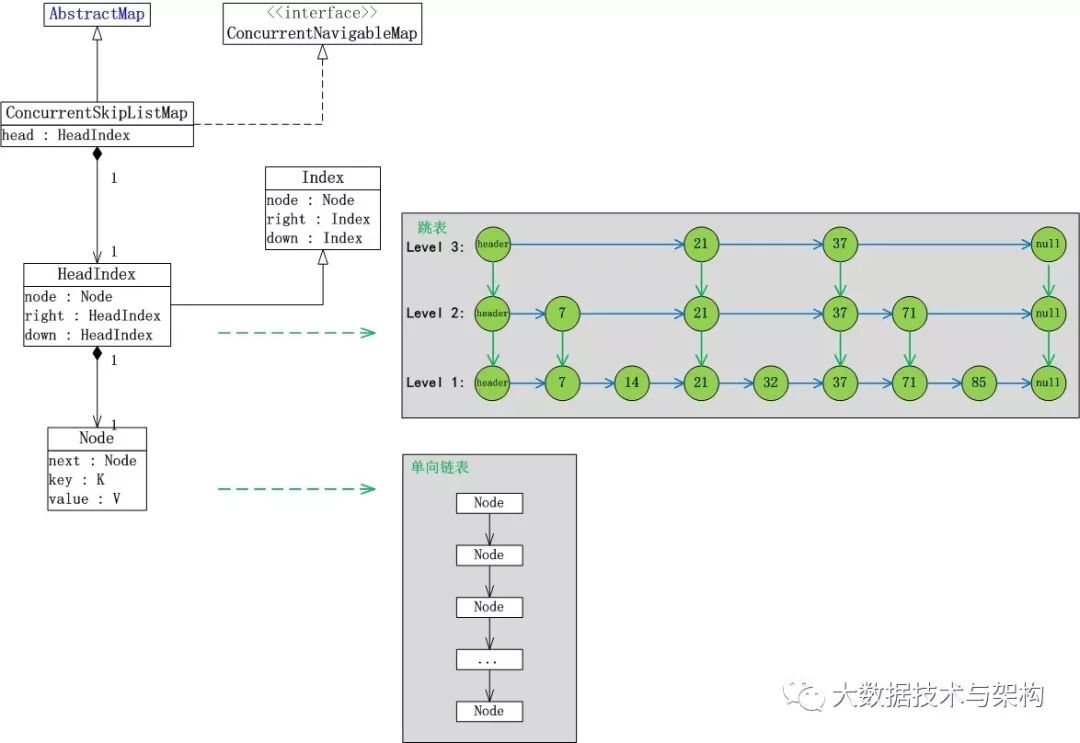
说明:
先以数据“7,14,21,32,37,71,85”序列为例,来对跳表进行简单说明。
跳表分为许多层(level),每一层都可以看作是数据的索引,这些索引的意义就是加快跳表查找数据速度。每一层的数据都是有序的,上一层数据是下一层数据的子集,并且第一层(level 1)包含了全部的数据;层次越高,跳跃性越大,包含的数据越少。
跳表包含一个表头,它查找数据时,是从上往下,从左往右进行查找。现在“需要找出值为32的节点”为例,来对比说明跳表和普遍的链表。
情况1:链表中查找“32”节点
路径如下图1-02所示:

需要4步(红色部分表示路径)。
情况2:跳表中查找“32”节点
路径如下图1-03所示:
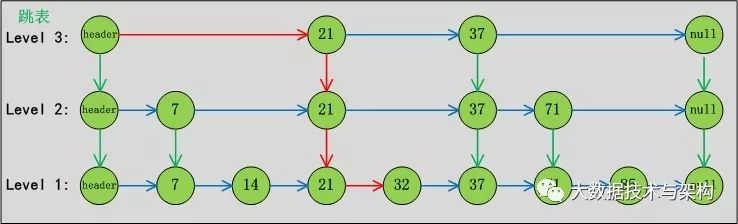
忽略索引垂直线路上路径的情况下,只需要2步(红色部分表示路径)。下面说说Java中ConcurrentSkipListMap的数据结构。
(01) ConcurrentSkipListMap继承于AbstractMap类,也就意味着它是一个哈希表。
(02) Index是ConcurrentSkipListMap的内部类,它与“跳表中的索引相对应”。HeadIndex继承于Index,ConcurrentSkipListMap中含有一个HeadIndex的对象head,head是“跳表的表头”。
(03) Index是跳表中的索引,它包含“右索引的指针(right)”,“下索引的指针(down)”和“哈希表节点node”。node是Node的对象,Node也是ConcurrentSkipListMap中的内部类。
4ConcurrentSkipListMap函数列表
// 构造一个新的空映射,该映射按照键的自然顺序进行排序。
ConcurrentSkipListMap()
// 构造一个新的空映射,该映射按照指定的比较器进行排序。
ConcurrentSkipListMap(Comparator<??super?K> comparator)
// 构造一个新映射,该映射所包含的映射关系与给定映射包含的映射关系相同,并按照键的自然顺序进行排序。
ConcurrentSkipListMap(Map<??extends?K,??extends?V> m)
// 构造一个新映射,该映射所包含的映射关系与指定的有序映射包含的映射关系相同,使用的顺序也相同。
ConcurrentSkipListMap(SortedMap<K,??extends?V> m)
// 返回与大于等于给定键的最小键关联的键-值映射关系;如果不存在这样的条目,则返回 null。
Map.Entry<K,V> ceilingEntry(K key)
// 返回大于等于给定键的最小键;如果不存在这样的键,则返回 null。
K ceilingKey(K key)
// 从此映射中移除所有映射关系。
void?clear()
// 返回此 ConcurrentSkipListMap 实例的浅表副本。
ConcurrentSkipListMap<K,V> clone()
// 返回对此映射中的键进行排序的比较器;如果此映射使用键的自然顺序,则返回 null。
Comparator<??super?K> comparator()
// 如果此映射包含指定键的映射关系,则返回 true。
boolean?containsKey(Object?key)
// 如果此映射为指定值映射一个或多个键,则返回 true。
boolean?containsValue(Object?value)
// 返回此映射中所包含键的逆序 NavigableSet 视图。
NavigableSet<K> descendingKeySet()
// 返回此映射中所包含映射关系的逆序视图。
ConcurrentNavigableMap<K,V> descendingMap()
// 返回此映射中所包含的映射关系的 Set 视图。
Set<Map.Entry<K,V>> entrySet()
// 比较指定对象与此映射的相等性。
boolean?equals(Object?o)
// 返回与此映射中的最小键关联的键-值映射关系;如果该映射为空,则返回 null。
Map.Entry<K,V> firstEntry()
// 返回此映射中当前第一个(最低)键。
K firstKey()
// 返回与小于等于给定键的最大键关联的键-值映射关系;如果不存在这样的键,则返回 null。
Map.Entry<K,V> floorEntry(K key)
// 返回小于等于给定键的最大键;如果不存在这样的键,则返回 null。
K floorKey(K key)
// 返回指定键所映射到的值;如果此映射不包含该键的映射关系,则返回 null。
V?get(Object?key)
// 返回此映射的部分视图,其键值严格小于 toKey。
ConcurrentNavigableMap<K,V> headMap(K toKey)
// 返回此映射的部分视图,其键小于(或等于,如果 inclusive 为 true)toKey。
ConcurrentNavigableMap<K,V> headMap(K toKey,?boolean?inclusive)
// 返回与严格大于给定键的最小键关联的键-值映射关系;如果不存在这样的键,则返回 null。
Map.Entry<K,V> higherEntry(K key)
// 返回严格大于给定键的最小键;如果不存在这样的键,则返回 null。
K higherKey(K key)
// 如果此映射未包含键-值映射关系,则返回 true。
boolean?isEmpty()
// 返回此映射中所包含键的 NavigableSet 视图。
NavigableSet<K> keySet()
// 返回与此映射中的最大键关联的键-值映射关系;如果该映射为空,则返回 null。
Map.Entry<K,V> lastEntry()
// 返回映射中当前最后一个(最高)键。
K lastKey()
// 返回与严格小于给定键的最大键关联的键-值映射关系;如果不存在这样的键,则返回 null。
Map.Entry<K,V> lowerEntry(K key)
// 返回严格小于给定键的最大键;如果不存在这样的键,则返回 null。
K lowerKey(K key)
// 返回此映射中所包含键的 NavigableSet 视图。
NavigableSet<K> navigableKeySet()
// 移除并返回与此映射中的最小键关联的键-值映射关系;如果该映射为空,则返回 null。
Map.Entry<K,V> pollFirstEntry()
// 移除并返回与此映射中的最大键关联的键-值映射关系;如果该映射为空,则返回 null。
Map.Entry<K,V> pollLastEntry()
// 将指定值与此映射中的指定键关联。
V put(K key, V value)
// 如果指定键已经不再与某个值相关联,则将它与给定值关联。
V putIfAbsent(K key, V value)
// 从此映射中移除指定键的映射关系(如果存在)。
V remove(Object?key)
// 只有目前将键的条目映射到给定值时,才移除该键的条目。
boolean?remove(Object?key,?Object?value)
// 只有目前将键的条目映射到某一值时,才替换该键的条目。
V replace(K key, V value)
// 只有目前将键的条目映射到给定值时,才替换该键的条目。
boolean?replace(K key, V oldValue, V newValue)
// 返回此映射中的键-值映射关系数。
int size()
// 返回此映射的部分视图,其键的范围从 fromKey 到 toKey。
ConcurrentNavigableMap<K,V> subMap(K fromKey,?boolean?fromInclusive, K toKey,?boolean?toInclusive)
// 返回此映射的部分视图,其键值的范围从 fromKey(包括)到 toKey(不包括)。
ConcurrentNavigableMap<K,V> subMap(K fromKey, K toKey)
// 返回此映射的部分视图,其键大于等于 fromKey。
ConcurrentNavigableMap<K,V> tailMap(K fromKey)
// 返回此映射的部分视图,其键大于(或等于,如果 inclusive 为 true)fromKey。
ConcurrentNavigableMap<K,V> tailMap(K fromKey,?boolean?inclusive)
// 返回此映射中所包含值的 Collection 视图。
Collection<V> values()5ConcurrentSkipListMap源码分析
下面从ConcurrentSkipListMap的添加,删除,获取这3个方面对它进行分析。
1. 添加
下面以put(K key, V value)为例,对ConcurrentSkipListMap的添加方法进行说明。
public?V?put(K key, V?value)?{
? ?if?(value?==?null)
? ? ? ?throw?new?NullPointerException();
? ?return?doPut(key,?value,?false);
}实际上,put()是通过doPut()将key-value键值对添加到ConcurrentSkipListMap中的。
doPut()的源码如下:
private?V?doPut(K kkey, V?value, boolean onlyIfAbsent)?{
? ?Comparable<? super K> key = comparable(kkey);
? ?for?(;;) {
? ? ? ?// 找到key的前继节点
? ? ? ?Node<K,V> b = findPredecessor(key);
? ? ? ?// 设置n为“key的前继节点的后继节点”,即n应该是“插入节点”的“后继节点”
? ? ? ?Node<K,V> n = b.next;
? ? ? ?for?(;;) {
? ? ? ? ? ?if?(n !=?null) {
? ? ? ? ? ? ? ?Node<K,V> f = n.next;
? ? ? ? ? ? ? ?// 如果两次获得的b.next不是相同的Node,就跳转到”外层for循环“,重新获得b和n后再遍历。
? ? ? ? ? ? ? ?if?(n != b.next)
? ? ? ? ? ? ? ? ? ?break;
? ? ? ? ? ? ? ?// v是“n的值”
? ? ? ? ? ? ? ?Object v = n.value;
? ? ? ? ? ? ? ?// 当n的值为null(意味着其它线程删除了n);此时删除b的下一个节点,然后跳转到”外层for循环“,重新获得b和n后再遍历。
? ? ? ? ? ? ? ?if?(v ==?null) { ? ? ? ? ? ? ??// n is deleted
? ? ? ? ? ? ? ? ? ?n.helpDelete(b, f);
? ? ? ? ? ? ? ? ? ?break;
? ? ? ? ? ? ? ?}
? ? ? ? ? ? ? ?// 如果其它线程删除了b;则跳转到”外层for循环“,重新获得b和n后再遍历。
? ? ? ? ? ? ? ?if?(v == n || b.value?==?null)?// b is deleted
? ? ? ? ? ? ? ? ? ?break;
? ? ? ? ? ? ? ?// 比较key和n.key
? ? ? ? ? ? ? ?int?c = key.compareTo(n.key);
? ? ? ? ? ? ? ?if?(c >?0) {
? ? ? ? ? ? ? ? ? ?b = n;
? ? ? ? ? ? ? ? ? ?n = f;
? ? ? ? ? ? ? ? ? ?continue;
? ? ? ? ? ? ? ?}
? ? ? ? ? ? ? ?if?(c ==?0) {
? ? ? ? ? ? ? ? ? ?if?(onlyIfAbsent || n.casValue(v,?value))
? ? ? ? ? ? ? ? ? ? ? ?return?(V)v;
? ? ? ? ? ? ? ? ? ?else
? ? ? ? ? ? ? ? ? ? ? ?break;?// restart if lost race to replace value
? ? ? ? ? ? ? ?}
? ? ? ? ? ? ? ?// else c < 0; fall through
? ? ? ? ? ?}
? ? ? ? ? ?// 新建节点(对应是“要插入的键值对”)
? ? ? ? ? ?Node<K,V> z =?new?Node<K,V>(kkey,?value, n);
? ? ? ? ? ?// 设置“b的后继节点”为z
? ? ? ? ? ?if?(!b.casNext(n, z))
? ? ? ? ? ? ? ?break; ? ? ? ??// 多线程情况下,break才可能发生(其它线程对b进行了操作)
? ? ? ? ? ?// 随机获取一个level
? ? ? ? ? ?// 然后在“第1层”到“第level层”的链表中都插入新建节点
? ? ? ? ? ?int?level = randomLevel();
? ? ? ? ? ?if?(level >?0)
? ? ? ? ? ? ? ?insertIndex(z, level);
? ? ? ? ? ?return?null;
? ? ? ?}
? ?}
}说明:doPut() 的作用就是将键值对添加到“跳表”中。
要想搞清doPut(),首先要弄清楚它的主干部分 —— 我们先单纯的只考虑“单线程的情况下,将key-value添加到跳表中”,即忽略“多线程相关的内容”。它的流程如下:
第1步:找到“插入位置”。
即,找到“key的前继节点(b)”和“key的后继节点(n)”;key是要插入节点的键。
第2步:新建并插入节点。
即,新建节点z(key对应的节点),并将新节点z插入到“跳表”中(设置“b的后继节点为z”,“z的后继节点为n”)。
第3步:更新跳表。
即,随机获取一个level,然后在“跳表”的第1层~第level层之间,每一层都插入节点z;在第level层之上就不再插入节点了。若level数值大于“跳表的层次”,则新建一层。
主干部分“对应的精简后的doPut()的代码”如下(仅供参考):
private?V?doPut(K kkey, V?value, boolean onlyIfAbsent)?{
? ?Comparable<? super K> key = comparable(kkey);
? ?for?(;;) {
? ? ? ?// 找到key的前继节点
? ? ? ?Node<K,V> b = findPredecessor(key);
? ? ? ?// 设置n为key的后继节点
? ? ? ?Node<K,V> n = b.next;
? ? ? ?for?(;;) {
? ? ? ? ? ?
? ? ? ? ? ?// 新建节点(对应是“要被插入的键值对”)
? ? ? ? ? ?Node<K,V> z =?new?Node<K,V>(kkey,?value, n);
? ? ? ? ? ?// 设置“b的后继节点”为z
? ? ? ? ? ?b.casNext(n, z);
? ? ? ? ? ?// 随机获取一个level
? ? ? ? ? ?// 然后在“第1层”到“第level层”的链表中都插入新建节点
? ? ? ? ? ?int?level = randomLevel();
? ? ? ? ? ?if?(level >?0)
? ? ? ? ? ? ? ?insertIndex(z, level);
? ? ? ? ? ?return?null;
? ? ? ?}
? ?}
}理清主干之后,剩余的工作就相对简单了。主要是上面几步的对应算法的具体实现,以及多线程相关情况的处理!
2. 删除
下面以remove(Object key)为例,对ConcurrentSkipListMap的删除方法进行说明。
public?V?remove(Object key)?{
? ?return?doRemove(key,?null);
}实际上,remove()是通过doRemove()将ConcurrentSkipListMap中的key对应的键值对删除的。
doRemove()的源码如下:
final V?doRemove(Object okey, Object?value)?{
? ?Comparable<? super K> key = comparable(okey);
? ?for?(;;) {
? ? ? ?// 找到“key的前继节点”
? ? ? ?Node<K,V> b = findPredecessor(key);
? ? ? ?// 设置n为“b的后继节点”(即若key存在于“跳表中”,n就是key对应的节点)
? ? ? ?Node<K,V> n = b.next;
? ? ? ?for?(;;) {
? ? ? ? ? ?if?(n ==?null)
? ? ? ? ? ? ? ?return?null;
? ? ? ? ? ?// f是“当前节点n的后继节点”
? ? ? ? ? ?Node<K,V> f = n.next;
? ? ? ? ? ?// 如果两次读取到的“b的后继节点”不同(其它线程操作了该跳表),则返回到“外层for循环”重新遍历。
? ? ? ? ? ?if?(n != b.next) ? ? ? ? ? ? ? ? ? ?// inconsistent read
? ? ? ? ? ? ? ?break;
? ? ? ? ? ?// 如果“当前节点n的值”变为null(其它线程操作了该跳表),则返回到“外层for循环”重新遍历。
? ? ? ? ? ?Object v = n.value;
? ? ? ? ? ?if?(v ==?null) { ? ? ? ? ? ? ? ? ? ?// n is deleted
? ? ? ? ? ? ? ?n.helpDelete(b, f);
? ? ? ? ? ? ? ?break;
? ? ? ? ? ?}
? ? ? ? ? ?// 如果“前继节点b”被删除(其它线程操作了该跳表),则返回到“外层for循环”重新遍历。
? ? ? ? ? ?if?(v == n || b.value?==?null) ? ? ?// b is deleted
? ? ? ? ? ? ? ?break;
? ? ? ? ? ?int?c = key.compareTo(n.key);
? ? ? ? ? ?if?(c <?0)
? ? ? ? ? ? ? ?return?null;
? ? ? ? ? ?if?(c >?0) {
? ? ? ? ? ? ? ?b = n;
? ? ? ? ? ? ? ?n = f;
? ? ? ? ? ? ? ?continue;
? ? ? ? ? ?}
? ? ? ? ? ?// 以下是c=0的情况
? ? ? ? ? ?if?(value?!=?null?&& !value.equals(v))
? ? ? ? ? ? ? ?return?null;
? ? ? ? ? ?// 设置“当前节点n”的值为null
? ? ? ? ? ?if?(!n.casValue(v,?null))
? ? ? ? ? ? ? ?break;
? ? ? ? ? ?// 设置“b的后继节点”为f
? ? ? ? ? ?if?(!n.appendMarker(f) || !b.casNext(n, f))
? ? ? ? ? ? ? ?findNode(key); ? ? ? ? ? ? ? ? ?// Retry via findNode
? ? ? ? ? ?else?{
? ? ? ? ? ? ? ?// 清除“跳表”中每一层的key节点
? ? ? ? ? ? ? ?findPredecessor(key); ? ? ? ? ??// Clean index
? ? ? ? ? ? ? ?// 如果“表头的右索引为空”,则将“跳表的层次”-1。
? ? ? ? ? ? ? ?if?(head.right ==?null)
? ? ? ? ? ? ? ? ? ?tryReduceLevel();
? ? ? ? ? ?}
? ? ? ? ? ?return?(V)v;
? ? ? ?}
? ?}
}说明:doRemove()的作用是删除跳表中的节点。
和doPut()一样,我们重点看doRemove()的主干部分,了解主干部分之后,其余部分就非常容易理解了。下面是“单线程的情况下,删除跳表中键值对的步骤”:
第1步:找到“被删除节点的位置”。
即,找到“key的前继节点(b)”,“key所对应的节点(n)”,“n的后继节点f”;key是要删除节点的键。
第2步:删除节点。
即,将“key所对应的节点n”从跳表中移除 -- 将“b的后继节点”设为“f”!
第3步:更新跳表。
即,遍历跳表,删除每一层的“key节点”(如果存在的话)。如果删除“key节点”之后,跳表的层次需要-1;则执行相应的操作!
主干部分“对应的精简后的doRemove()的代码”如下(仅供参考):
final V doRemove(Object?okey,?Object?value) {
? ?Comparable<??super?K> key = comparable(okey);
? ?for?(;;) {
? ? ? ?// 找到“key的前继节点”
? ? ? ?Node<K,V> b = findPredecessor(key);
? ? ? ?// 设置n为“b的后继节点”(即若key存在于“跳表中”,n就是key对应的节点)
? ? ? ?Node<K,V> n = b.next;
? ? ? ?for?(;;) {
? ? ? ? ? ?// f是“当前节点n的后继节点”
? ? ? ? ? ?Node<K,V> f = n.next;
? ? ? ? ? ?// 设置“当前节点n”的值为null
? ? ? ? ? ?n.casValue(v,?null);
? ? ? ? ? ?// 设置“b的后继节点”为f
? ? ? ? ? ?b.casNext(n, f);
? ? ? ? ? ?// 清除“跳表”中每一层的key节点
? ? ? ? ? ?findPredecessor(key);
? ? ? ? ? ?// 如果“表头的右索引为空”,则将“跳表的层次”-1。
? ? ? ? ? ?if?(head.right ==?null)
? ? ? ? ? ? ? ?tryReduceLevel();
? ? ? ? ? ?return?(V)v;
? ? ? ?}
? ?}
}3. 获取
下面以get(Object key)为例,对ConcurrentSkipListMap的获取方法进行说明
public?V?get(Object?key) {
? ?return?doGet(key);
}doGet的源码如下:
private?V doGet(Object?okey) {
? ?Comparable<??super?K> key = comparable(okey);
? ?for?(;;) {
? ? ? ?// 找到“key对应的节点”
? ? ? ?Node<K,V> n = findNode(key);
? ? ? ?if?(n ==?null)
? ? ? ? ? ?return?null;
? ? ? ?Object?v = n.value;
? ? ? ?if?(v !=?null)
? ? ? ? ? ?return?(V)v;
? ?}
}说明:doGet()是通过findNode()找到并返回节点的。
private?Node<K,V>?findNode(Comparable<? super K> key)?{
? ?for?(;;) {
? ? ? ?// 找到key的前继节点
? ? ? ?Node<K,V> b = findPredecessor(key);
? ? ? ?// 设置n为“b的后继节点”(即若key存在于“跳表中”,n就是key对应的节点)
? ? ? ?Node<K,V> n = b.next;
? ? ? ?for?(;;) {
? ? ? ? ? ?// 如果“n为null”,则跳转中不存在key对应的节点,直接返回null。
? ? ? ? ? ?if?(n ==?null)
? ? ? ? ? ? ? ?return?null;
? ? ? ? ? ?Node<K,V> f = n.next;
? ? ? ? ? ?// 如果两次读取到的“b的后继节点”不同(其它线程操作了该跳表),则返回到“外层for循环”重新遍历。
? ? ? ? ? ?if?(n != b.next) ? ? ? ? ? ? ? ?// inconsistent read
? ? ? ? ? ? ? ?break;
? ? ? ? ? ?Object v = n.value;
? ? ? ? ? ?// 如果“当前节点n的值”变为null(其它线程操作了该跳表),则返回到“外层for循环”重新遍历。
? ? ? ? ? ?if?(v ==?null) { ? ? ? ? ? ? ? ?// n is deleted
? ? ? ? ? ? ? ?n.helpDelete(b, f);
? ? ? ? ? ? ? ?break;
? ? ? ? ? ?}
? ? ? ? ? ?if?(v == n || b.value?==?null) ?// b is deleted
? ? ? ? ? ? ? ?break;
? ? ? ? ? ?// 若n是当前节点,则返回n。
? ? ? ? ? ?int?c = key.compareTo(n.key);
? ? ? ? ? ?if?(c ==?0)
? ? ? ? ? ? ? ?return?n;
? ? ? ? ? ?// 若“节点n的key”小于“key”,则说明跳表中不存在key对应的节点,返回null
? ? ? ? ? ?if?(c <?0)
? ? ? ? ? ? ? ?return?null;
? ? ? ? ? ?// 若“节点n的key”大于“key”,则更新b和n,继续查找。
? ? ? ? ? ?b = n;
? ? ? ? ? ?n = f;
? ? ? ?}
? ?}
}说明:findNode(key)的作用是在返回跳表中key对应的节点;存在则返回节点,不存在则返回null。
先弄清函数的主干部分,即抛开“多线程相关内容”,单纯的考虑单线程情况下,从跳表获取节点的算法。
第1步:找到“被删除节点的位置”。
根据findPredecessor()定位key所在的层次以及找到key的前继节点(b),然后找到b的后继节点n。
第2步:根据“key的前继节点(b)”和“key的前继节点的后继节点(n)”来定位“key对应的节点”。
具体是通过比较“n的键值”和“key”的大小。如果相等,则n就是所要查找的键。
6ConcurrentSkipListMap示例
import java.util.*;
import java.util.concurrent.*;
/*
* ? ConcurrentSkipListMap是“线程安全”的哈希表,而TreeMap是非线程安全的。
*
* ? 下面是“多个线程同时操作并且遍历map”的示例
* ? (01) 当map是ConcurrentSkipListMap对象时,程序能正常运行。
* ? (02) 当map是TreeMap对象时,程序会产生ConcurrentModificationException异常。
public class ConcurrentSkipListMapDemo1 {
? ?// TODO: map是TreeMap对象时,程序会出错。
? ?//private static Map<String, String> map = new TreeMap<String, String>();
? ?private static Map<String, String> map = new ConcurrentSkipListMap<String, String>();
? ?public static void main(String[] args) {
? ?
? ? ? ?// 同时启动两个线程对map进行操作!
? ? ? ?new MyThread("a").start();
? ? ? ?new MyThread("b").start();
? ?}
? ?private static void?printAll() {
? ? ? ?String key, value;
? ? ? ?Iterator iter = map.entrySet().iterator();
? ? ? ?while(iter.hasNext()) {
? ? ? ? ? ?Map.Entry entry = (Map.Entry)iter.next();
? ? ? ? ? ?key = (String)entry.getKey();
? ? ? ? ? ?value = (String)entry.getValue();
? ? ? ? ? ?System.out.print("("+key+", "+value+"), ");
? ? ? ?}
? ? ? ?System.out.println();
? ?}
? ?private static class MyThread extends Thread {
? ? ? ?MyThread(String name) {
? ? ? ? ? ?super(name);
? ? ? ?}
? ? ? ?@Override
? ? ? ?public void?run() {
? ? ? ? ? ? ? ?int i = 0;
? ? ? ? ? ?while?(i++ < 6) {
? ? ? ? ? ? ? ?// “线程名” +?"序号"
? ? ? ? ? ? ? ?String val = Thread.currentThread().getName()+i;
? ? ? ? ? ? ? ?map.put(val,?"0");
? ? ? ? ? ? ? ?// 通过“Iterator”遍历map。
? ? ? ? ? ? ? ?printAll();
? ? ? ? ? ?}
? ? ? ?}
? ?}
}其中一次运行结果:
(a1, 0), (a1, 0), (b1, 0), (b1, 0),
(a1, 0), (b1, 0), (b2, 0),?
(a1, 0), (a1, 0), (a2, 0), (a2, 0), (b1, 0), (b1, 0), (b2, 0), (b2, 0), (b3, 0),?
(b3, 0), (a1, 0),?
(a2, 0), (a3, 0), (a1, 0), (b1, 0), (a2, 0), (b2, 0), (a3, 0), (b3, 0), (b1, 0), (b4, 0),?
(b2, 0), (a1, 0), (b3, 0), (a2, 0), (b4, 0),?
(a3, 0), (a1, 0), (a4, 0), (a2, 0), (b1, 0), (a3, 0), (b2, 0), (a4, 0), (b3, 0), (b1, 0), (b4, 0), (b2, 0), (b5, 0),?
(b3, 0), (a1, 0), (b4, 0), (a2, 0), (b5, 0),?
(a3, 0), (a1, 0), (a4, 0), (a2, 0), (a5, 0), (a3, 0), (b1, 0), (a4, 0), (b2, 0), (a5, 0), (b3, 0), (b1, 0), (b4, 0), (b2, 0), (b5, 0), (b3, 0), (b6, 0),?
(b4, 0), (a1, 0), (b5, 0), (a2, 0), (b6, 0),?
(a3, 0), (a4, 0), (a5, 0), (a6, 0), (b1, 0), (b2, 0), (b3, 0), (b4, 0), (b5, 0), (b6, 0),结果说明:
示例程序中,启动两个线程(线程a和线程b)分别对ConcurrentSkipListMap进行操作。以线程a而言,它会先获取“线程名”+“序号”,然后将该字符串作为key,将“0”作为value,插入到ConcurrentSkipListMap中;接着,遍历并输出ConcurrentSkipListMap中的全部元素。 线程b的操作和线程a一样,只不过线程b的名字和线程a的名字不同。
当map是ConcurrentSkipListMap对象时,程序能正常运行。如果将map改为TreeMap时,程序会产生ConcurrentModificationException异常。
内容总结
以上是互联网集市为您收集整理的大数据成神之路-Java高级特性增强(ConcurrentSkipListMap)全部内容,希望文章能够帮你解决大数据成神之路-Java高级特性增强(ConcurrentSkipListMap)所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。