# -*- coding: utf8 -*-‘‘‘__author__ = ‘dabay.wang@gmail.com‘56: Merge Intervalshttps://oj.leetcode.com/problems/merge-intervals/Given a collection of intervals, merge all overlapping intervals.For example,Given [1,3],[2,6],[8,10],[15,18],return [1,6],[8,10],[15,18].===Comments by Dabay===这道题想起来比较简单,实现的时候恼火。技巧在与,不是一个个地插入到已有的序列,而是把已有的序列插入到一个标...
题目:Given two sorted integer arrays A and B, merge B into A as one sorted array.Note:You may assume that A has enough space (size that is greater or equal to m + n) to hold additional elements from B. The number of elements initialized in A and B are m and nrespectively. 代码:oj测试通过 Runtime: 58 ms 1class Solution:2# @param A a list of integers 3# @param m an integer, length of A 4# @param...
Ref:https://nbviewer.jupyter.org/github/pydata/pydata-book/blob/2nd-edition/ch08.ipynbimport pandas as pddf1 = pd.DataFrame({‘key‘: [‘b‘, ‘b‘, ‘a‘, ‘c‘, ‘a‘, ‘a‘, ‘b‘],‘data1‘: range(7)})
df2 = pd.DataFrame({‘key‘: [‘a‘, ‘b‘, ‘d‘],‘data2‘: range(3)})
df1
df2 pd.merge(df1, df2) #不指定on则以两个DataFrame的列名交集做为连接键 ,这里指的是"key"pd.merge(df1,df2,on = "key")...
目录
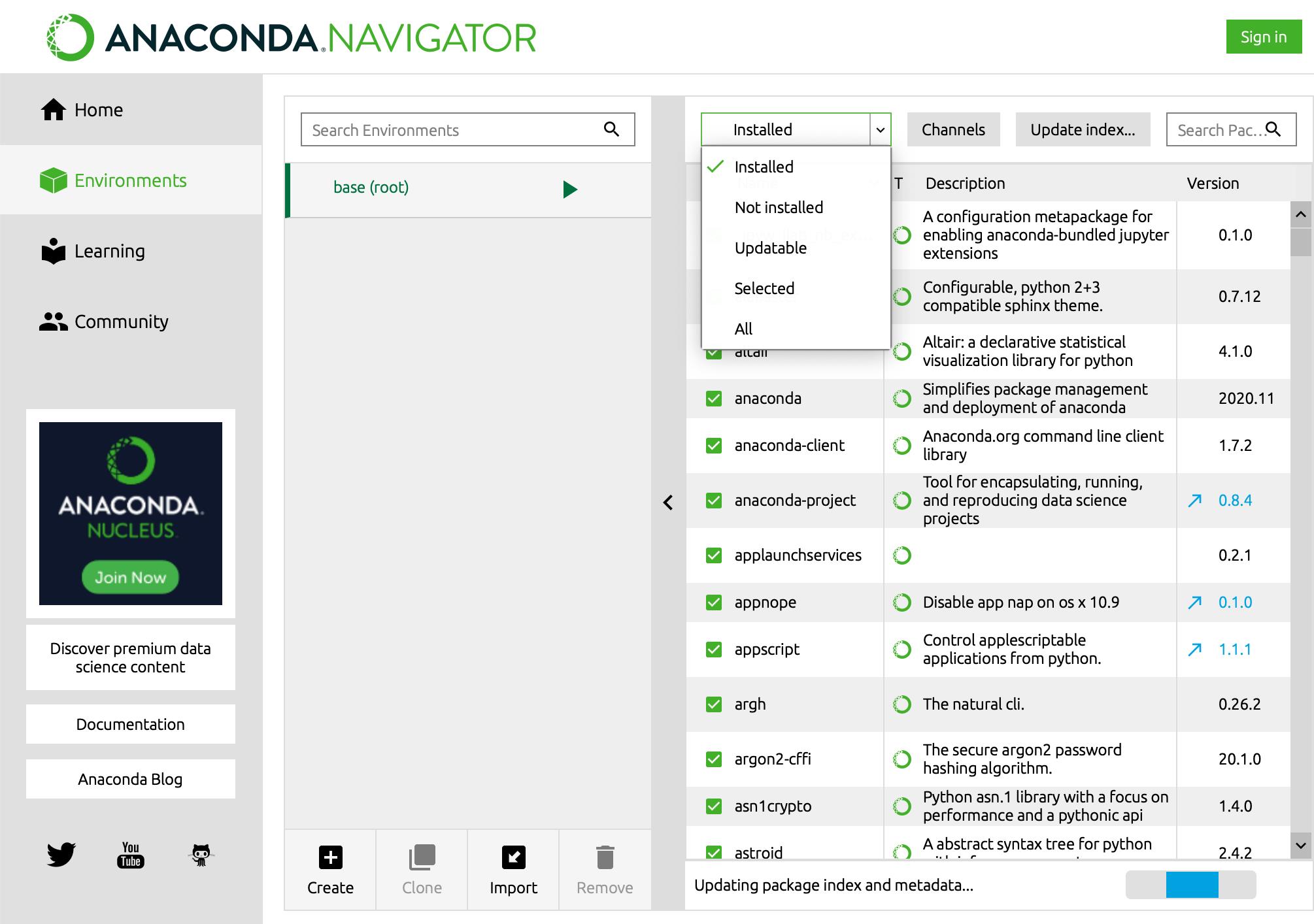
使用Anaconda创建jupyter笔记本利用python,合并表格的两种方法,merge&join使用Anaconda创建jupyter笔记本Anaconda可以在官网下载。 添加新工具包的方法: 在Environments中搜索,并添加即可。
利用python,合并表格的两种方法,merge&join
以2021美赛数据集为例。首先合并表格要注意的是设置表格的表头,即这一语句: 是将表格第一列设置为合并表格的索引,这样合并表格的时候就会合并两个表格第一列的元素相同的行。
id1....
@本文来源于公众号:csdn2299,喜欢可以关注公众号 程序员学府
今天小编就为大家分享一篇在Pandas中DataFrame数据合并,连接(concat,merge,join)的实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧
最近在工作中,遇到了数据合并、连接的问题,故整理如下,供需要者参考~
一、concat:沿着一条轴,将多个对象堆叠到一起
concat方法相当于数据库中的全连接(union all),它不仅可以指定连接的方式(outer joi...
目录行的unionpd.concatdf.append列的joinpd.concatpd.mergedf.join行列转置pivotstack & unstackmelt
本文示例数据下载,密码:vwy3
import pandas as pd# 数据是之前在cnblog上抓取的部分文章信息
df = pd.read_csv('./data/SQL测试用数据_20200325.csv',encoding='utf-8')# 为了后续演示,抽样生成两个数据集df1 = df.sample(n=500,random_state=123)
df2 = df.sample(n=600,random_state=234)# 保证有较多的交集
# 比例抽样是有...
合并数据集
一.merge函数参数表格merge(left,right,how=inner,on=None,left_on=None,right_on=None,left_index=False,right_index=False,sort=False,suffixes= (_x,_y),copy=True,indicator=False,validate=None)
二.concat函数参数表格
注:当索引有重复项时,不能用concat。
下列:q = pd.DataFrame([[1,2],[3,4]])
r = pd.DataFrame([[1,2],[5,6]], columns=['a','b'])
pd.merge(q, r, left_on=q.columns, right_on=r.columns, how='left')引发错误:ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()以下不是:q = pd.DataFrame([[1,2],[3,4]])
r = pd.DataFrame([[1,2],[5,6]], columns=['a','b'])
pd.merge(q, r, left_on=q.columns.tolist(...
从python docs开始.
我在很多地方都找到了该算法,例如here、here和here.它们都没有提到算法的名称.
我需要为论文提供参考,所以请指出正确的方向.解决方法:这称为“多路合并”,由Donald Knuth在“计算机编程的艺术”第三卷-排序和搜索的第5.4.1节中进行了描述.
我正在尝试合并一组预排序的文件,其中每个文件中的每一行都是一个整数:for line in heapq.merge(*files):排序成功完成,但比较以字符串而不是整数的形式在文件内容上进行.如何强制进行整数比较?解决方法:尝试这个:for line in heapq.merge(*(map(int, file) for file in files)):在比较过程中,这不会将字符串解释为整数,但实际上会即时将其更改为整数.因此,结果是整数,而不是字符串.当然可以根据需要将其转换回字符串:for line ...
我有两个共享项目编号的独立数据框.在type_df中,项目编号是索引.在time_df中,项目编号是一列.我想计算type_df中项目类型为2的行数.我试图用pandas.merge()来做这个.它在使用两列时效果很好,但不是索引.我不确定如何引用索引,如果合并甚至是正确的方法.import pandas as pd
type_df = pd.DataFrame(data = [['Type 1'], ['Type 2']], columns=['Project Type'], index=['Project2', 'Project1'])
time_df = pd.DataFrame(data = [['...
我想在Keras中合并两个LSTM模型.我见过许多导入Merge的例子:from keras.layers import Merge当我这样做时,我收到导入错误.
ImportError:无法导入名称’Merge’.
是否有一些重构,现在Merge在其他地方?解决方法:从keras 2开始,模块keras.layers.merge没有通用的公共Merge-Layer.相反,你应该直接导入子类,如keras.layers.Add或keras.layers.Concatenate等(或者它们的功能接口使用相同的名称小写:keras.layers.add,keras.layers.co...
python中pandas数据匹配常用merge函数,其实merge函数就类似于excel中的vlookup hlookup lookup,最近excel又出了一个逆天的xlookup函数,默默地推荐一下,嘿嘿
转载自:https://www.cnblogs.com/stream886/p/6022049.html,感谢博主
一定要看里面的图,很形象
使用Pandas进行数据匹配
本文转载自:蓝鲸的网站分析笔记
原文链接:使用Pandas进行数据匹配
目录
merge()介绍
inner模式匹配
lefg模式匹配
right模式匹配
outer模式匹...
我将目录中的所有文件连接成一个,但是一些文件具有不同数量的条目 – 当文件中没有该键的值时,如何放置NaN?
例如:
file1.csNUM, NAME, ORG, DATA1,AAA,10,123.41,AAB,20,176.51,AAC,30,133.5文件2. CSNUM, NAME, ORG, DATA1,AAA,10,111.41,AAC,30,122.52,BBA,12,156.7期望的输出NUM, NAME, ORG, File1, File2 ....1, AAA, 10, 123.4, 111.41, AAB, 20, 176.5, NaN1, AAC, 30, 133.5, 122.52, BBA, 12, NaN, 156.7.....这就是我...
HSV
hue 色调
saturation 饱和度
value
OpenCV是0-180,主要是为了可以用Uint8,一个字节表示做颜色物体跟踪的关键步骤
YCrCb
提取人的皮肤
最常见的HSV与RGB YUV与RGB转换# -*- coding:utf-8 -*-
# Linda Li 2019/8/15 10:19 cv_01_色彩空间 PyCharm
import cv2 as cv# RGB色彩空间 黑色(0,0,0) 白色 255,255,255
def color_space_demo(image):"""BGR图像转换其他色彩空间"""# 转换为灰度图像gray = cv.cvtColor(image, cv.COLOR_...