首页 / 算法 / 猴子也能看懂的算法(1)并查集
猴子也能看懂的算法(1)并查集
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了猴子也能看懂的算法(1)并查集,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3791字,纯文字阅读大概需要6分钟。
内容图文
并查集")
猴子也能看懂的并查集算法
并查集用于对集合进行操作。主要的操作包括查找(find)与合并(union)。并查集是最小生成树Kruscal算法的重要组成部分。
当给出两个元素之间的关系时,将这两个元素列入一个集合。
当有许多组这样的关系时,我们需要知道哪些元素是属于同一个集合的,总共有多少个集合,最大的集合包括了多少元素等等。
初始版本
用编号最小的元素标记所在集合。
定义数组set[1…n],其中set[i]表示元素i所在集合。
| i | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| set[i] | 1 | 2 | 1 | 2 | 5 |
表格中有共有三个集合{1,3},{2,4},{5}
如果我们希望找到某个元素i所在的集合,我们只需知道set[i]所代表的值即可。因此find所需的时间是O(1)。
进行合并操作时,设有集合{1,3},{2,4},想让他们成为一个集合,我们必须遍历set[1…n]找到所有set[i]为2的元素,将他们的“头领”2改为前一个集合的“头领”1。复杂度O(N),当N较大时,进行一次操作就要遍历一次数组,这显然是不可以接受的。
下面是代码。
Find1(x)
{
return set[x];
}
Union1(a,b)//i,j的作用是什么?
{ i = min(a,b);
j = max(a,b);
for (k=1; k<=N; k++) {
if (set[k] == j)
set[k] = i;
}
}
树结构的引入
既然链式结构对查找的要求不高而对合并的要求很高,用树结构如何?
我们知道,当一棵树并入另一棵树时,不需要把树底下的所有元素都并到另一棵树下,只需要把他们的“头领”并到另一棵树下即可。
思路参照下列表格:
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| set[i] | 1 | 2 | 1 | 2 | 5 | 3 | 6 |
若要寻找元素7所在的集合。
1.找到set[7]对应的元素6
2.判断元素6是不是一个集合的头领(如何判断?)
3.如果不是头领,寻找元素6的头领set[6]
迭代。
在此不加说明的贴上树实现的代码。
Find2(x)
{ r = x;
while (set[r] != r)
r = set[r];
return r;
}
Union2(a, b)
{
set[a] = b;
}
(Union2函数中没有要求(a,b)的大小,会产生什么影响?会影响最终结果吗?)
产生的影响是,“头领”的序号可能会比自己的序号更小,不会影响最终结果。
此代码中 查找的复杂度O(logN),最坏复杂度O(N),合并的复杂度O(1),看起来快了很多,但是有无本质改进?
参考下列集合
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| set[i] | 1 | 1 | 2 | 3 | 4 | 5 | 6 |
它本质上只有一个集合{1,2,3,4,5,6}然而查找与线性表相同,复杂度为O(N),如何避免最坏情况?
树结构加强版
当我们想把一棵树与另一棵树合并时,上者是随机的将两棵树中的某一节点合并。譬如:有集合{1,2,3,4,5}和集合{6,7,8,9,10}。
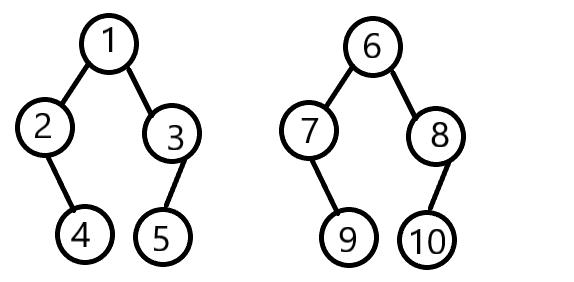
当我想要把这两棵树合并时,我可以选择其中任意两个节点,连接。
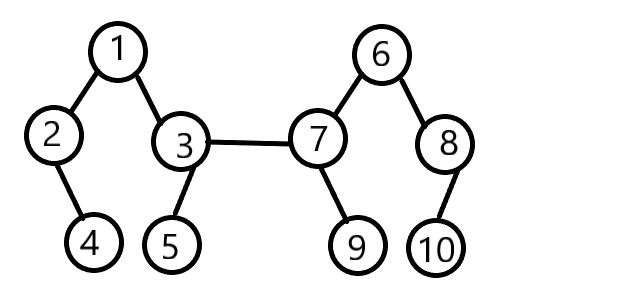
得到了一颗不是非常美观的树,但它仍符合我们对并查集查找的需求,只不过,如果这样进行构造,十分有可能生成上一版本中提到的链式“树”。这时我们会想,根节点相连,的话不就可以避免这个问题了吗?如果后来的树(元素)在合并时都与根节点连在一起,不就形成树了吗?
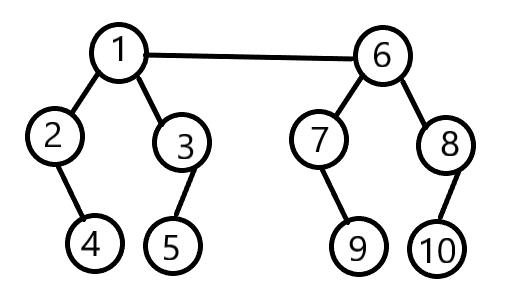
于是就有了加强版:
Find2(x)
{
r = x;
while (set[r] != r)
r = set[r];
return r;
}
Union3(a,b)
{
if (height[a] == height[b] {
height[a]= height[a] + 1;
set[b] = a;
}
else if (height[a] < height[b]
set[a] = b;
else
set[b] = a;
}
Find函数较上个版本没有发生特别大的变化。我们主要说Union函数:这里加入了一个height数组,即树的高度
#(为什么不直接节点合并?)
因为当这样形成的树比较美观×
这样查找效率较高√
#(为什么树的高度相同时合并后高度+1?)
参照上图。
并查集最终无敌版——路径压缩
当查找路径较长,查找次数较多时,往往会消耗大量时间。我们能否让这棵树动态的修改自己查找的路径,使得树从“瘦高”变得“宽矮”。
参考下图:
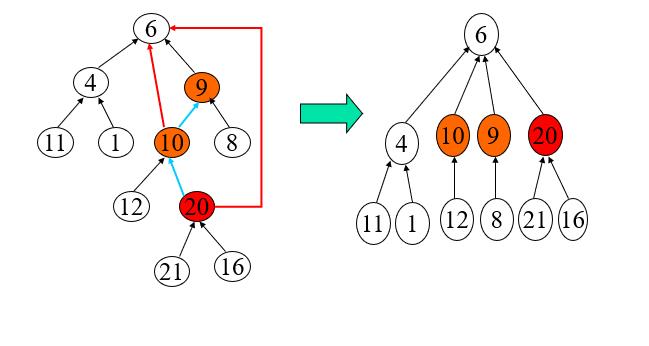
当我们查找元素20所在集合时,我们经过的路径为20-10-9-6.我要将这一路径压缩,使得我所经过的节点都直接链接“头领”,这样下一次查找20等结点的效率大大增加。这便是路径压缩——本质是树的压缩。
Find3(x)
{
r = x;
while (set[r] <> r) //循环结束,则找到根节点
r = set[r];
i = x;
while (i <> r) //本循环修改查找路径中所有节点
{
j = set[i];
set[i] = r;
i = j;
}
至此,我们便已完成了并查集的两个最终函数:
我们需要准备一个set[i]=i的初始集合(所有人的头领都是自己)
和一个height[i]=1的高度集合
Find(int x)
{
int r,i,j;
r = x;
while (set[r] <> r) //循环结束,则找到根节点
r = set[r];
i = x;
while (i <> r) //本循环修改查找路径中所有节点
{
j = set[i];
set[i] = r;
i = j;
}
}
Union(int a,int b)
{
if (height[a] == height[b] {
height[a]= height[a] + 1;
set[b] = a;
}
else if (height[a] < height[b]
set[a] = b;
else
set[b] = a;
}
输入某两个数(a,b)之间存在关系时,实际上就是Union(a,b)
查询集合数量,即遍历元素,寻找set[i]=i的元素数量
题目表:
hdoj1213
hdoj1325
hdoj1856
下一节:最小生成树
内容总结
以上是互联网集市为您收集整理的猴子也能看懂的算法(1)并查集全部内容,希望文章能够帮你解决猴子也能看懂的算法(1)并查集所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。