首页 / PYTHON / python爬取疫情数据
python爬取疫情数据
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了python爬取疫情数据,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3636字,纯文字阅读大概需要6分钟。
内容图文

具体要求:
从网页爬取全国疫情分布情况,读取入库结合图形化展示。
思路:
- 抓取
- 分析
- 存储
在项目导入requests和PyMysql包;
发送请求,并打印数据状态码;
分析爬取到的数据:

name是国家/省/市的名字;id为地区编号;lastUpdateTime是最后更新时间;total为累计数据;today为今天新增数据;confirm、suspect、heal、dead分别为确诊、疑似、治愈、死亡人数;
建表为:

连接并将数据存入数据库:


conn = pymysql.connect(
host='localhost', # 我的IP地址
port=3306, # 不是字符串不需要加引号。
user='root',
password='123456',
db='test',
charset='utf8'
)
cursor = conn.cursor() # 获取一个光标
id = 0;
for dict in province_list:
sql = 'insert into yiqing_copy1 (province,date,total_confirm,total_suspect,total_heal,total_dead,today_confirm,today_suspect,today_heal,today_dead,id) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s);'
province=dict['name']
date = dict['lastUpdateTime']
total_confirm=dict['total']['confirm']
total_suspect=dict['total']['suspect']
total_heal=dict['total']['heal']
total_dead=dict['total']['dead']
today_confirm=dict['today']['confirm']
today_suspect=dict['today']['suspect']
today_heal=dict['today']['heal']
today_dead=dict['today']['dead']
id=id+1
sys.stdout.write( dict['name'] + ' ')
cursor.execute(sql, [province, date,total_confirm, total_suspect,total_heal,total_dead,today_confirm,today_suspect,today_heal,today_dead,id])
View Code
完整代码:
import requests
import time, json
import sys;
import pymysql
def get_wangyi_request():
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-total'
headers = {
'accept': '*/*',
'accept-encoding': 'gzip,deflate,br',
'accept-language': 'en-US,en;q=0.9,zh-CN;q = 0.8,zh;q = 0.7',
'origin': 'https://wp.m.163.com',
'referer': 'https://wp.m.163.com/',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-ite',
'user-agent': 'Mozilla/5.0(WindowsNT10.0;Win64;x64) AppleWebKit/37.36 (KHTML, likeGecko) Chrome/82.0.4056.0 Safari/537.36 Edg/82.0.432.3'
}
result = requests.get(url, headers=headers)
return result
def print_mess1(string: str, dict1total: dict):
sys.stdout.write(string + '确诊: ' + str(dict1total['confirm'] if dict1total['confirm'] != None else 0))
sys.stdout.write(' ')
sys.stdout.write(string + '疑似: ' + str(dict1total['suspect'] if dict1total['suspect'] != None else 0))
sys.stdout.write(' ')
sys.stdout.write(string + '治愈: ' + str(dict1total['heal'] if dict1total['heal'] != None else 0))
sys.stdout.write(' ')
sys.stdout.write(string + '死亡: ' + str(dict1total['dead'] if dict1total['dead'] != None else 0))
if __name__ == '__main__':
result = get_wangyi_request()
json_str = json.loads(result.text)['data']
# print(json_str.keys())
# dict_keys(['chinaTotal', 'chinaDayList', 'lastUpdateTime', 'areaTree'])
print(json_str['lastUpdateTime'])
province_list = json_str['areaTree'][0]['children']
# 每个省份包含如下的键
# dict_keys(['today', 'total', 'extData', 'name', 'id', 'lastUpdateTime', 'children'])
conn = pymysql.connect(
host='localhost', # 我的IP地址
port=3306, # 不是字符串不需要加引号。
user='root',
password='123456',
db='test',
charset='utf8'
)
cursor = conn.cursor() # 获取一个光标
id = 0;
for dict in province_list:
sql = 'insert into yiqing_copy1 (province,date,total_confirm,total_suspect,total_heal,total_dead,today_confirm,today_suspect,today_heal,today_dead,id) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s);'
province=dict['name']
date = dict['lastUpdateTime']
total_confirm=dict['total']['confirm']
total_suspect=dict['total']['suspect']
total_heal=dict['total']['heal']
total_dead=dict['total']['dead']
today_confirm=dict['today']['confirm']
today_suspect=dict['today']['suspect']
today_heal=dict['today']['heal']
today_dead=dict['today']['dead']
id=id+1
sys.stdout.write( dict['name'] + ' ')
cursor.execute(sql, [province, date,total_confirm, total_suspect,total_heal,total_dead,today_confirm,today_suspect,today_heal,today_dead,id])
print()
conn.commit()
cursor.close()
conn.close()
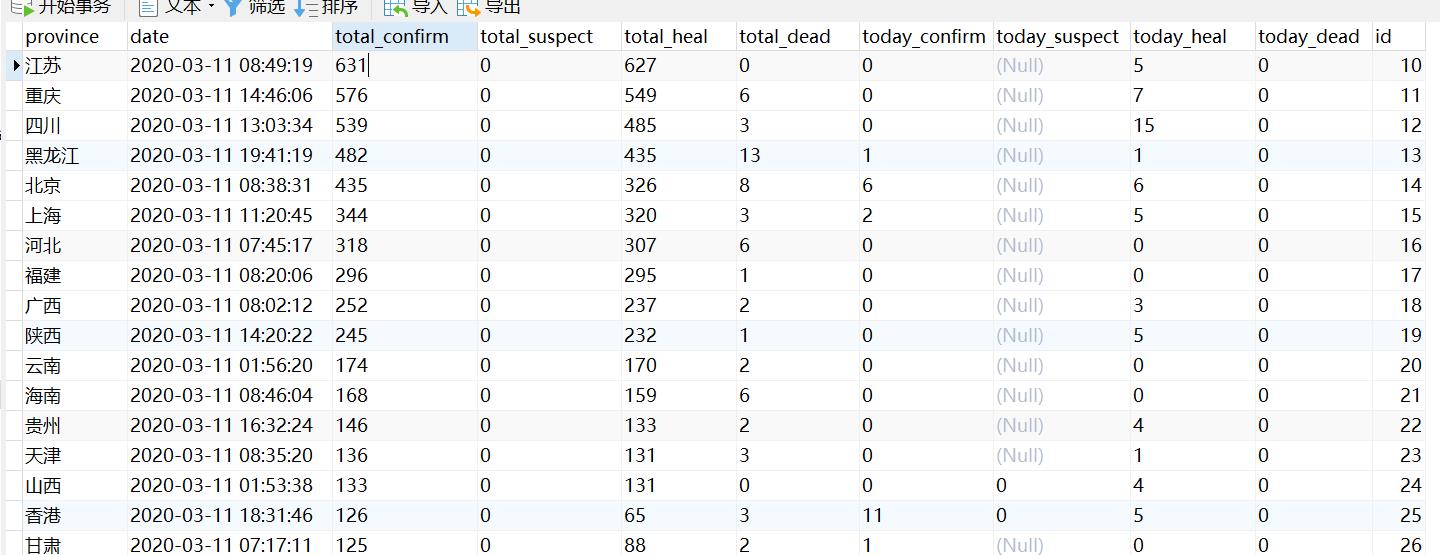
数据库:
内容总结
以上是互联网集市为您收集整理的python爬取疫情数据全部内容,希望文章能够帮你解决python爬取疫情数据所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。
来源:【匿名】