首页 / 算法 / 如何在报表中实现算法的可挂接需求
如何在报表中实现算法的可挂接需求
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了如何在报表中实现算法的可挂接需求,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3408字,纯文字阅读大概需要5分钟。
内容图文

在报表项目中,有些报表中部分数据的计算方法会经常改变。例如:某企业员工的实际工资是通过绩效得分计算出的,而绩效的算法可能经常变动,需要在不改动其他代码的情况下用新算法替换旧算法。一般我们都会想到用 Java 来实现计算,从而实现动态可挂接计算模块,但是这种方式可能存在缺乏基础类库、占用多余内存等问题。
这里我们介绍一种可以实现低耦合、热部署的动态挂接算法,使得解决此类问题更具结构性优势,这就是结合集算器使用润乾报表。下图对比了润乾报表实现的可挂接算法和其他报表工具 +java 实现可挂接算法的在系统结构上的差异:
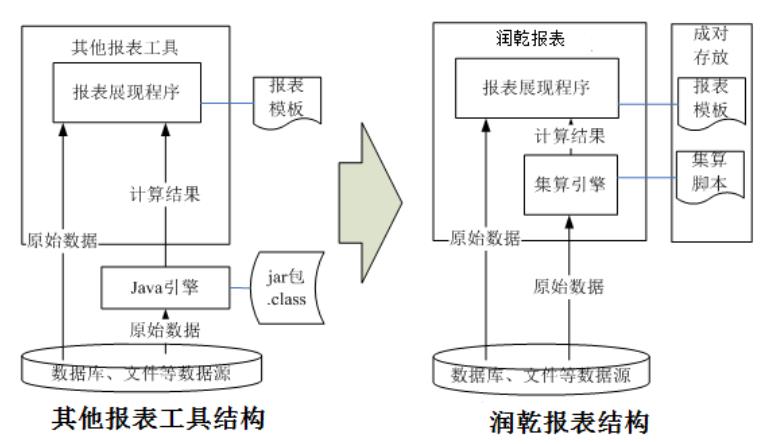
可以看出,java 程序必须要编译、打包才能更新,无法实现热部署。而集算脚本是解释执行的,脚本文件同时也是可执行文件,所以可以直接进行替换更新。同时,集算脚本可以和报表模板成对存放,在代码管理上更为清晰、便利。
下面就用员工绩效工资的例子来说明润乾报表的实现方法,并和其他报表工具 +Java 的实现方式做一下比较。
员工绩效工资报表如下:
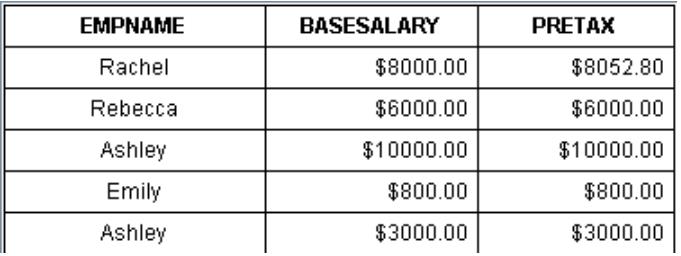
报表格式比较简单,但是计算方法相对复杂,而且经常变动,算法部分需要动态挂接才能满足需求。
具体实现步骤如下:
1、编写集算器脚本
| A | B | C | |
| 1 | =connect("demo") | ||
| 2 | =A1.query("select p.EMPLOYEEID as empID, p.EVALUATION as score,e.dept as dept, e.NAME as empName,p.BONUS as baseSalary from performance as p,employee as e where p.EMPLOYEEID=e.EID and e.gender=?",gender) | ||
| 3 | =A2.derive(PRETAX) | ||
| 4 | =sales=A3.select(DEPT=="Sales") | ||
| 5 | for sales | if A5.BASESALARY<2000 | >A5.PRETAX=A5.BASESALARY*(1+A5.SCORE/100) |
| 6 | else if A5.BASESALARY<4000 | >A5.PRETAX=A5.BASESALARY*(1+A5.SCORE*0.9/100) | |
| 7 | else if A5.BASESALARY<6000 | >A5.PRETAX=A5.BASESALARY*(1+A5.SCORE*0.8/100) | |
| 8 | else | >A5.PRETAX=A5.BASESALARY*(1+A5.SCORE*0.6/100) | |
| 9 | =normal=A3.select(DEPT!="Sales") | ||
| 10 | =A9.run(PRETAX=BASESALARY) | ||
| 11 | =sales|normal | ||
| 12 | =A11.new(EMPNAME,BASESALARY,PRETAX) | >A1.close() | |
| 13 | result A12 | ||
A2 单元格有个输入参数 gender,来自于查询页面。A13 单元格是将结果返回给报表页面。A2 到 A12 之间是绩效工资的计算方法,具体算法不是本文重点,这里不详细介绍,只要知道这部分可以随时替换就可以了。
2、配置报表数据集
润乾报表的报表模板可以定义集算器数据集来调用可挂接计算模块:
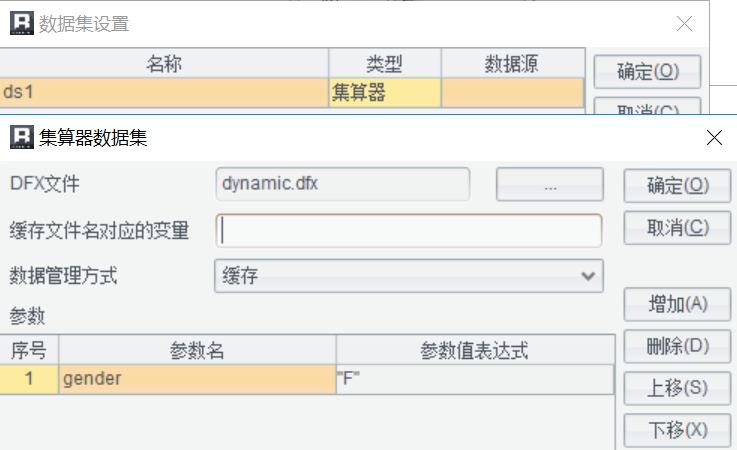
其中,gender 参数是 dynamic.dfx 的输入参数,数据集 ds1 接收 dynamic.dfx 返回的结果集。
可以看到集算器脚本 dynamic.dfx 和报表模板之间的耦合程度非常低。如果要改变绩效工资的计算方法,只需要编写一个新的 dynamic.dfx,替换服务器上原有的 dfx 文件即可。因为 dfx 脚本是解释执行的,所以可以不停机替换,实现真正的热部署。
3、设计报表模板
在润乾报表设计器中像使用普通数据集一样设计报表模板即可。如下图所示:

从这个例子可以看出润乾报表实现的可挂接算法,相比普通报表工具 +Java 的实现方式有多方面的优势。
1、dynamic.dfx 可以使用润乾报表提供的多种函数方法:分组、汇总、排序、过滤、关联、唯一值、交集、排名等等。Java 程序员必须手工编写这些基础算法。而将这些基础算法直接实现在业务逻辑中显然是不合理的,因为这会导致每个计算模块重复书写类似的代码,使得计算模块过于庞大、可读性变差。理想的作法是先实现一套基础算法类库,再在计算模块中调用,而应用程序员很难设计出完备性和系统性优秀的基础算法类库,因此常常使代码的耦合性高,稳定性差,最终导致计算模块维护困难。
润乾报表的集算引擎本身就是这样一套精心设计的完备基础类库,经过简单的学习,应用程序员只需要 JAVA 十分之一的代码量就可以实现同样功能的计算模块,开发效率更高。
2、JAVA 代码需要重新编译,部署起来比较麻烦;当可挂接的计算模块较多时,不论是否还要使用它们,这些 Java class/jar 都会占据内存空间而无法释放,对性能有一定的影响。
润乾报表的集算器引擎和脚本文件是分开的,耦合性很低,维护起来更加方便。另外,集算脚本无需编译即可使用,是真正的热部署。脚本程序不会事先加载到内存,而是使用时再加载,计算完立刻释放,不会长期占用内存。
内容总结
以上是互联网集市为您收集整理的如何在报表中实现算法的可挂接需求全部内容,希望文章能够帮你解决如何在报表中实现算法的可挂接需求所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。