java数据结构和算法⑨——高效查找(二分查找和Hash查找)
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了java数据结构和算法⑨——高效查找(二分查找和Hash查找),小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2649字,纯文字阅读大概需要4分钟。
内容图文
")
二分查找
需要有序
时间复杂度为Nlog(N)
Hash查找
jdk1.7时hashmap的结构就是hash数组和链表
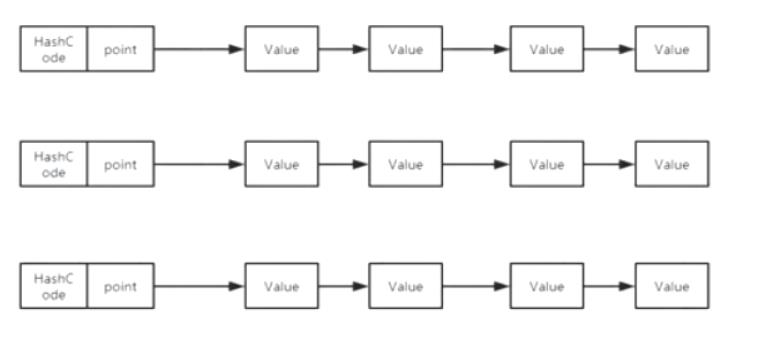
jdk1.8后hashmap在链表数据个数大于8时会转换成红黑树
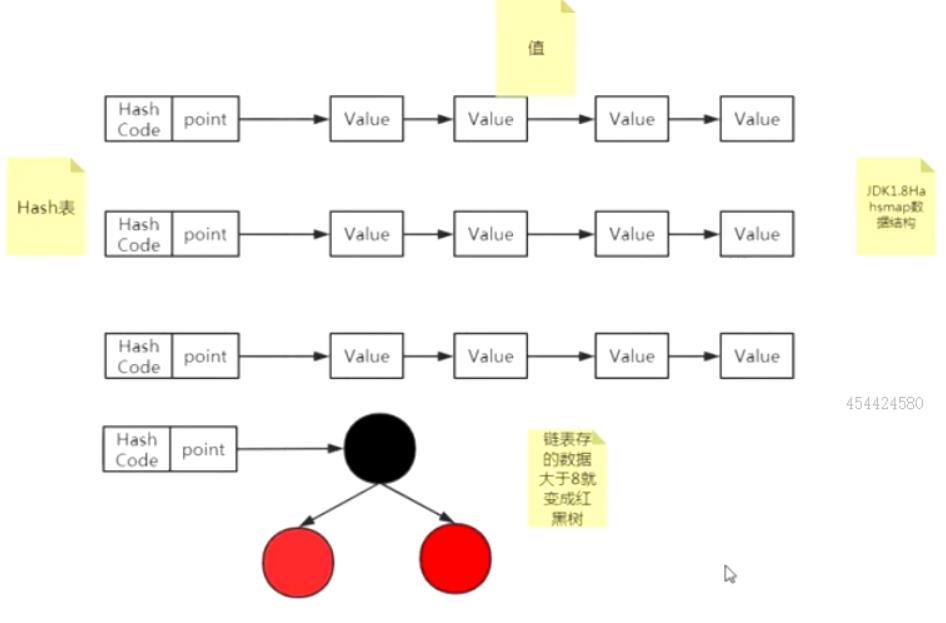
所以jdk1.8中hashmap用到的数据结构有hash数组链表和红黑树
class Entry<K, V> {
K key;
V value;
Entry<K, V> next; // 表示指针 我只写链表
int cap; // 表示hash冲突的个数
public Entry(K key, V value, Entry<K, V> next) {
this.key = key;
this.value = value;
this.next = next;
}
}
public class MyHashMap<K, V> {
// 定义一个默认的空间 存多少个数据
private static final int DEFAULT_SIZE = 1 << 4; // 其实是2网左移4位 就是16 10000
private Entry<K, V>[] data; // 存数据的hash表
private int capacity; // 空间 会扩容的
private int size = 0; // 大小
public MyHashMap() {
this(DEFAULT_SIZE);
}
public MyHashMap(int capacity) {
if (capacity <= 0)
capacity = DEFAULT_SIZE;
this.capacity = capacity;
data = new Entry[capacity];
}
public void put(K key, V value) {
// HashMap key可以为null吗? value 呢?
if (key == null)
return;
int hash = hash(key); // 取hash
// if(size >= 0.75*capacity)
// resize 会把所有的数据重新计算一次 会清空
Entry<K, V> newE = new Entry<K, V>(key, value, null); // 表示新进来一个数据
// 判断有没有hash冲突
Entry<K, V> hashM = data[hash];
while (hashM != null) { // 表示有hash冲突
if (hashM.key.equals(key)) { // 表示是一样的key 覆盖 1->2 1->3 那就变成3了
hashM.value = value;
return;
}
hashM = hashM.next; // 链表后移
}
//少了一个红黑树 就是这个hashM空间大于等于8
//TreeMap
newE.next = data[hash]; // 表示加入链表 这样就加在了链表的头
data[hash] = newE;
size++;
}
public V get(K key) {
int hash = hash(key);
Entry<K, V> entry = data[hash];
// 链表遍历取数据
while (entry != null) {
if (entry.key.equals(key)) { //key 的hashCode 和value比较的时候究竟怎么用找value的时候用equals,并不是hashCode一样.
return entry.value;
}
entry = entry.next;
}
return null;
}
private int hash(K key) { // JDK自己测试出来的 我也不知道怎么就这么好用
int h = 0;
if (key == null)
h = 0;
else {
h = key.hashCode() ^ (h >>> 16); // 无符号右移16位
}
return h % capacity;
}
public static void main(String[] args) {
MyHashMap<String, String> map = new MyHashMap<>();
map.put("1", "a");
map.put("2", "b");
map.put("3", "c");
System.out.println(map.get("1"));
System.out.println(map.get("4"));
//ThreadPoolExecutor 线程池
//Executor executor
//设计模式 单例模式
//数据结构与算法+Java基础+设计模式
//hashCode相等的 值就一定相等吗? 不一定 所以在得出value的是要用equls
}
}
HashMap和HashTable的区别
- 线程同步,安全性问题:hashMap不行,因为有多线程,如果硬要在多线程中用HashMap 那么就只有GET。经典例子就是缓存不会更新,全局过滤。在一个代码中,每次new。
- 效率问题:HashMap效率高
- NULL值问题:不能用NULL的 key
LinkedHashMap
HashMap存进去跟取出来的顺序不一致,LinkedHashMap则可以保证有序,Key和value允许空值,线程非安全,Key值有序。
内容总结
以上是互联网集市为您收集整理的java数据结构和算法⑨——高效查找(二分查找和Hash查找)全部内容,希望文章能够帮你解决java数据结构和算法⑨——高效查找(二分查找和Hash查找)所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。
来源:【匿名】