MongoDB的核心概念和术语解释
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了MongoDB的核心概念和术语解释,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含4772字,纯文字阅读大概需要7分钟。
内容图文

MongoDB之所以流行,是因为它的特点 : 灵活、强大、易扩展的通用型数据库 。应用面很广。
- 可以做一个小型项目的数据库;
- 处理网站实时数据,处理实时的数据插入、更新、查询
- 作为缓存层, mongo是介于关系型和非关系型数据库之间,可以作为持久化缓存层
- 适合多态服务器的数据库,比如几十台服务器的数据库,支持MapReduce
说了这么多,MongoDB是什么,简单说一下
-
MongoDB
是一个“面向文档”的数据库,不是关系型数据库,没有行(row)的概念 ,只有更为灵活的“文档(document)”模型, 可以用一条记录表现复杂的层次关系,有点类似Json[ { "first_name" :"Taylor", "last_name":"Edward", "title" : "soft Architect", "salary" : 7500, "hire_date" : "2011-10-12", "hobby" :["travel","music","eat"], "contact":{ "email": "vd@edward.com", "phone":3333 } }]上边的数据格式,在mongo中可以利用一条记录插入,是不是很灵活。
其次,关系型数据库,都是预定义模式,插入的都是按照规格插入,跟表格一样,行列对照的数据,比如
insert into courses (name,submission_date) values("数学",NOW()); insert into courses (name,submission_date) values("English",NOW());两条插入数据都是行列对照的,而mongoDB不再采用这种严格的模式 ,文档的key-value 不再是固定类型,比如
db.products.insertOne( { _id: 10, item: "box", qty: 20 } ); db.products.insertOne( { _id: 10, item: ["box","circle"], qty: [20,30] ,name : 'Zhangsan'} );没有固定的模式(schema),对于开发者来说,根据需求添加和删除字段变得非常容易。
再说一下,mongoDB的友好特性
-
mongoDB易于扩展
Web项目,飞速扩展的数据集,需要开发者去扩展数据库。 一般两种选择,纵向选择更强的计算机、横向选择更多的机器。 对于mongoDB,面向文档的模型,天然支持数据分片,自动处理跨集群的数据和负载,不需开发者考虑扩展,扩容的时候,只需要向集群中添加新服务器即可。
后面的博客,回来描述一下,mongoDB如何搭建集群
-
mongoDB功能丰富
- 通用性数据库,支持增删改查。
- 天然支持集群, 同时让mongo不会支持关系型数据库中的复杂事务(比如多行的事务),但也有自己特点的事务
- 支持索引,提高查询效率。有 唯一索引、复合索引、全文索引等
- 支持聚合,MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似sql语句中的 count(*)
集合计算每个作者所写的文章数, 类似下边sqldb.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}])select by_user, count(*) from mycol group by by_user - 支持特殊集合类型,比如某个时刻会过期的数据
- 支持非常易用的协议,用于的存储大文件和文件元数据
-
强大的性能
mongo的文档中,提到mongo可以对文档做动态填充,可以预分配数据文件以利用额外空间换取性能稳定,用尽可能多的内存作为缓存,尽可能的提供高性能
mongo的文档模型
-
mongodb的数据结构
基本示意图
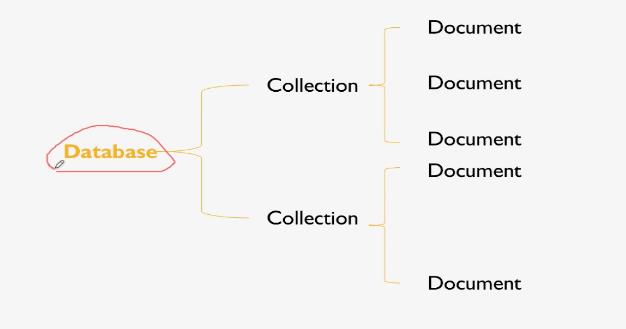
- Database : 数据库, 一般一个项目中会有一个database
- collection : 相当于table ( 比如一个 订单表 ),一个拥有动态模式(dynamic schema)的表
- document : 相当于一个table中一行数据 ( 比如订单表的 一条记录 )
-
文档
是一个键值对的集合,类似json结构。 相当于关系型数据库中的一行记录, 可以包含多种数据类型的键值对,结构灵活,比如下边的document,一条记录中包含了 字符串类型、数字类型、数组、对象
employee :[ { "title" : "soft Architect", "salary" : 7500, "hire_date" : "2011-10-12", "hobby" :["travel","music","eat"], "contact":{ "email": "vd@edward.com", "phone":3333 } }]但是 文档中,key-value是区分类型、大小写的,比如下边的两对 key-value都不是相同的 ;
{age : 11} {age :'age'} //类型不一样,不是相同的键值对 {age : 11} {Age :11} // 大小写不一样,不是相同的key-value此外不能存在重复的键 ,下边的是不允许的
{name : 'zhangsan1',name :'zhangsan2'}和json不一样, documet是有序的,比如下边的两个是不相同的,当然通常情况下,顺序是不重要的
{name : 'lisi',age 11} {age 11,name : 'lisi'} -
集合
集合从概念上可以看为关系型数据库的一张表 , 不过一个集合中可以存储 不对称的document , 比如下边代码, 这是集合的 动态模式 (Dynamic schema)db.people.insertOne({name:'lisi', class:'一班'}) db.people.insertOne({name:'lisan',company:'微软'}) db.people.insertOne({name:12345})虽然语法上,是支持这种模式的,但是实际上如果各种各样格式的document放到一个集合中,对于开发者是相当不友好的,不利于开发 ; 此外, 查询的时候,比如name字段 有的是存储字符串, 有的存储数组类型,一个字段存储不同的数据格式,会导致查询速度变慢 。
因此, 建议是把同类型的文档放到一个集合里,数据会集中,不同类型的文档拆分为不同的集合,每次查询相应集合 ,速度也会很快。 因为,索引的创建是按照集合来定义的,在一个集合中只放入一个类型的文档,可以更有效的对集合进行索引
比如上边的集合拆分成三个集合, 学生、工作者、机器人
db.stu.insertOne({name:'lisi', class:'一班'}) db.worker.insertOne({name:'lisan',company:'微软'}) db.robot.insertOne({name:1234})集合会有子集合,比如上边的employee.contact
-
数据库
多个集合组成数据库,mongodb中每个数据库有独立权限,存储在自己的文件中,获取集合需要用数据库名称.集合名称基本操作 :
-
show dbs : 显示数据库
-
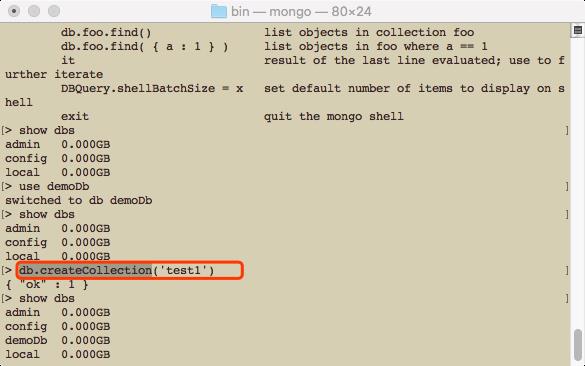
use demodb : 会创建一个新的数据库
但是show dbs不会显示(因为是空的 ,没有collection)
-
db.createCollection() 创建一个collection
-
db.getCollectionNames( ) : 或取当前db中的所有集合
-
db.drop :删除数据库
use demoDb切换到一个数据库后,db指向的就是这个数据的指针,可以利用这个指针做各种操作
-
内容总结
以上是互联网集市为您收集整理的MongoDB的核心概念和术语解释全部内容,希望文章能够帮你解决MongoDB的核心概念和术语解释所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。