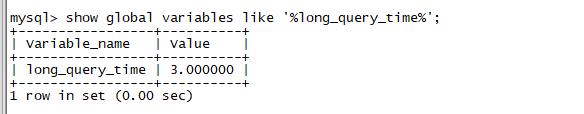原文地址: http://blog.sina.com.cn/s/blog_3c9872d00101p4f0.htmlNutch 2.2.1发布快两月了,该版本与Nutch之前版本相比,有较大变化,特别是与MySQL联合应用的安装和配置过程有不少地方容易出错。本人在安装过程中也遇到了不少麻烦,大多问题通过baidu和google也没有找到解决方法,自己只能通过看代码和分析日志并试错,最终搞定了所遇到的各种问题,现将重要安装和配置过程整理如下。1. MySQL数据库配置l my.ini配置分别在[cl...
python3.5先安装库或者扩展1 requests第三方扩展库 pip3 install requests2 pymysqlpip3 install pymysql3 lxmlpip3 install lxml4 贴个代码#!/usr/bin/env python
# coding=utf-8import requests
from bs4 import BeautifulSoup
import pymysqlprint(‘连接到mysql服务器...‘)
db = pymysql.connect("localhost","root","root","python")
print(‘连接上了!‘)
cursor = db.cursor()
cursor.execute("DROP TABLE IF EXISTS COLO...
通过shell脚本抓取存储home用户的空间使用情况,写到excel文件里,再导入到mysql数据库,最后通过grafana进行展示
vi aa.sh#!/bin/bashDate=date +"%Y-%m-%d %H:%M:%S"Date2=date +"%Y-%m-%d"Dir=/logs/Homes/bin/rm -rf $Dir/quota2.txt/bin/touch $Dir/quota2.txt/usr/bin/ssh 10.0.0.10 "quota report -x" | grep home > $Dir/quota.txt/usr/bin/ssh 10.0.0.20 "quota report -x" | grep home2 >> $Dir/quota.txt/bin/cat $Dir/...
最近学习python网络爬虫,所以自己写了一个简单的程序练练手(呵呵。。)。我使用的环境是python3.6和mysql8.0,抓取目标网站为百度热点(http://top.baidu.com/)。我只抓取了实时热点内容,其他栏目应该类似。代码中有两个变量SECONDS_PER_CRAWL和CRAWL_PER_UPDATE_TO_DB,前者为抓取频率,后者为抓取多少次写一次数据库,可自由设置。我抓取的数据内容是热点信息,链接,关注人数和时间。其在内存中存放的结构为dict{tuple(热点...
基本要素 最近用户反馈部署在RAC节点1的OGG的抓取进程已经停止运行几天了,希望排查下原因,让其恢复正常。问题分析 步骤一:查看日志 通过info all命令,查看当前抓取进程的状态,如下,状态为ABENDED,这时我们最简单的方式就是查看OGG的错误日志信息,该信基本要素最近用户反馈部署在RAC节点1的OGG的抓取进程已经停止运行几天了,希望排查下原因,让其恢复正常。
问题分析步骤一:查看日志通过info all命令,查看当前抓取进程的...
post'0','pwd' => '1',
);
/*
$pageContents = HttpClient::quickPost('http://xxxxxxxxx',$params);
echo $pageContents;*/
$client = new HttpClient('xxxxxx');
$client->setDebug(true);
$client->post('/action',$params);
echo $client->getContent();
// foreach (json_decode($client->getContent(), true) as $item)
// echo $item['name'].'';?> '0','pwd' => '1',
);
/*
$pageContents = HttpClient::quickPost('http:...
抓取的网页如何存入mysql数据库写的一个PHP代码(test.php):$url = "http://www.baidu.com/";? $contents = file_get_contents($url);? echo $contents;?>? 如何把抓取的这个网页数据mysql数据库中呢? 表是Page 字段1:Pageid | 字段2:Pagetext求代码------解决方案--------------------不就是一句 insert into 了?值都有了,字段也有了。。。
------解决方案--------------------若果pageid是自增的。则空缺也可。$sql="i...
抓取網頁資料如何存入mysql資料庫請問以下的Code有沒有什麼問題呢??主要是要抓取table內指數的資料,表是stock(內無資料),程序執行後stock表內仍是空白,連接資料庫是沒問題的,請幫忙協助修改為正確的代碼,謝謝!!$contents = file_get_contents('http://www.indexq.org');preg_match_all('//iUs', $contents, $match);mysql_connect("localhost", "root", "root") or die("無法連結主機");mysql_select_db("testdb") or die("無...
2.7.10 (default, Jun 5 2015, 17:56:24)
[GCC 4.4.4 20100726 (Red Hat 4.4.4-13)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import MySQLdb
Traceback (most recent call last):File "<stdin>", line 1, in <module>
ImportError: No module named MySQLdb 如果出现:ImportError: No module named MySQLdb则说明python尚未支持mysql,需要手工安装,请参考步骤2;如果没有报错...
scrapy+webkit:
如结构图③。
scrapy不能实现对javascript的处理,所以须要webkit解决问题。开源的解决方式能够选择scrapinghub的scrapyjs或者功能更强大的splash.关于scrapywebkit的使用后期进行分析。
scrapy+django:
如结构图④。
django实现的配置界面主要是对抓取系统的管理和配置,包含:网站feed、页面模块抽取、报表系统的反馈等等。请直接參考:
[1]高速构建实时抓取集群
[2]淘宝摘星
文章链接:http://blog.csdn.net/u0...
mysql -h192.168.100.206 -uroot -p
Enter password:
ERROR 1045 (28000): Access denied for user ‘root‘@‘192.168.11.201‘ (using password: YES)输入正确的密码进入并进行一系列操作[root@localhost ~]# mysql -h192.168.100.206 -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 442447
Server version: 5.5.25-log Source distributionCopyright (c) 2...
脚本实现:获取51cto网站某大牛文章的url,并存储到数据库中。#!/usr/bin/env python
#coding:utf-8
from bs4 import BeautifulSoup
import urllib
import re
import MySQLdb
k_art_name = []
v_art_url = []
db = MySQLdb.connect(‘192.168.115.5‘,‘blog‘,‘blog‘,‘blog‘)
cursor = db.cursor()
for page in range(1,5):
page = str(page)
url = ‘http://yujianglei.blog.51cto.com/all/7215578/page/‘ + page
reque...
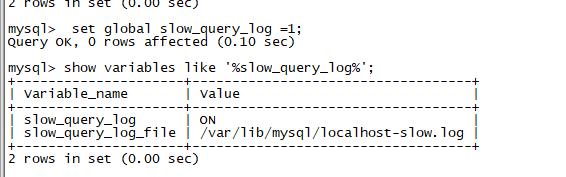
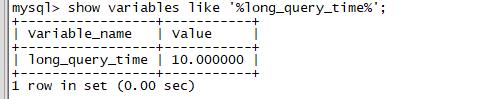
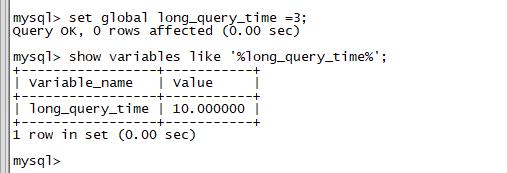
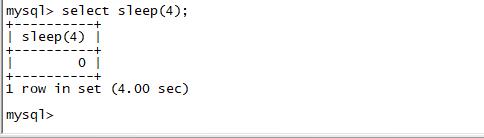
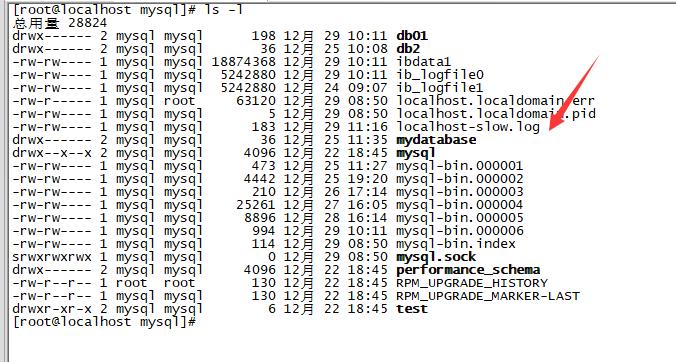
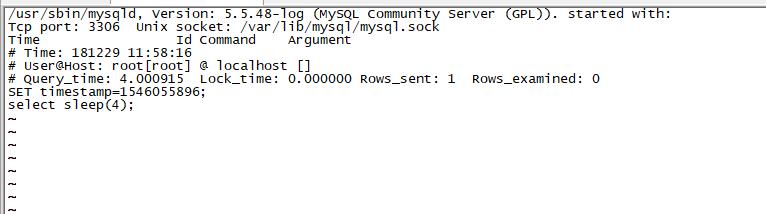
),首先要考虑是否因,SQL语句引起数据库慢,如果情况比较紧急,我们就要立刻 SHOW FULL PROCESSLIST; 去查看,但我建议大家使用-e参数,采用非交互的方式,因为这样可以使用grep等命令,对结果进行过滤,更方便直观的看到结果一、抓SQL慢查询语句的方法,有2种: 1,临时紧急抓取通过SHOW FULL PROCESSLIST; 的方式,执行几次,有相同语句,就可能是SQL慢查询语句;SHOW FULL PROCESSLIST; #查看MySQL 在运行的线程这个命令中最关...
1、抓取连接脚本---从繁重的重复工作中解脱出来为了使切换的过程更高效并解放自己的双手,编写了简单的shell脚本,定时抓取连接并存储至核心数据库,简单的例子:#!/bin/bash
StatFile="/var/log/status/processlist.txt"
#获取IP信息
IP=`/sbin/ifconfig | egrep -A 1 "eth[0-4] " | egrep "inet " | egrep -v "19...
https://www.cnblogs.com/dennis-liucd/p/7669161.html
https://www.cnblogs.com/kingwolfofsky/archive/2011/08/14/2138081.htmlPython爬虫抓取东方财富网股票数据并实现MySQL数据库存储标签:sky l数据库 href blog tps 抓取 com wol arc 本文系统来源:https://www.cnblogs.com/ilovecpp/p/12729224.html