Ubuntu 16.04后台运行scrapy爬虫程序
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Ubuntu 16.04后台运行scrapy爬虫程序,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含858字,纯文字阅读大概需要2分钟。
内容图文

某些爬虫程序需要运行很长时间才能将数据爬完,爬取太快呢又会被网站给封禁。你又不想一直开着电脑连续开几天,太麻烦。。。
其实有个好方法,你可以把爬虫放在阿里云服务器运行,这样你就不需要管了,但是你如果在Ubuntu或阿里云上直接:
scrapy crawl spider_name 或python run.py的话
当你关闭链接阿里云的xshell时,程序会直接停掉不会继续运行。
今天给大家分享一个在阿里云服务器后台运行你的scrapy爬虫代码的命令,可以使你的爬虫在服务器后台一直运行,关闭连接也没事。
nohup python -u run.py > spider_house.log 2>&1 &
run.py为你自己写的scrapy爬虫的运行文件:
from scrapy.cmdline import execute
execute(['scrapy','crawl','house'])
执行完命令后会返回给你一个进程ID,此时你的爬虫就已经在该进程中运行了,你可以用下边命令查看后台该进程:
ps -aux #a:显示所有程序 u:以用户为主的格式来显示 x:显示所有程序,不以终端机来区分
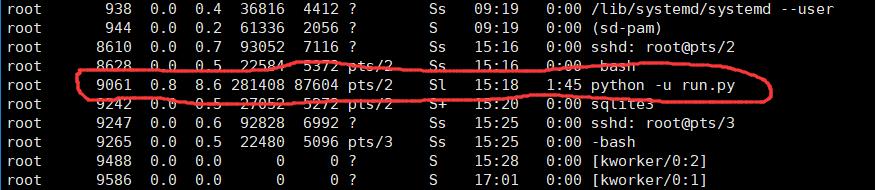
只要找到返回给你的进程pid,说明你的爬虫正在运行。
如下是我的运行进程:
内容总结
以上是互联网集市为您收集整理的Ubuntu 16.04后台运行scrapy爬虫程序全部内容,希望文章能够帮你解决Ubuntu 16.04后台运行scrapy爬虫程序所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。