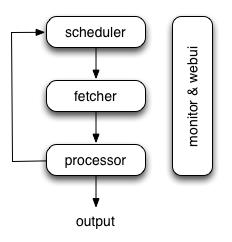
Scrapy单机架构在这里scrapy的核心是scrapy引擎,它通过里面的一个调度器来调度一个request的队列,将request发给downloader,然后来执行request请求但是这些request队列都是维持在本机上的,因此如果要多台主机协同爬取,需要一个request共享的机制——requests队列,在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享爬取队列。单主机爬虫架构调度器负责从队列中调度requests进行爬取,而...
分布式爬虫分布式概述? 基于多台电脑组建一个分布式机群,然后让机群中的每一台电脑执行同一组程序,然后让它们对同一个网站的数据进行分布爬取作用:提升爬虫数据的效率实现:基于scrapy+redis的形式实现分布式,scrapy结合这scrapy-redis组件实现的分布式原生scrapy无法实现分布式原因:? 1.调度器无法被分布式机群共享? 2.管道无法被共享scrapy-redis组件的作用:提供可以被共享的调度器和管道环境安装:
1.redis? 2.pip In...
scrapy-redis 分布式爬虫爬取房天下网站所有国内城市的新房和二手房信息先完成单机版的爬虫,然后将单机版爬虫转为分布式爬虫爬取思路1. 进入 https://www.fang.com/SoufunFamily.htm 页面,解析所有的省份和城市,获取到城市首页链接
2. 通过分析,每个城市的新房都是在首页链接上添加newhouse和house/s/字符串,二手房 都死在首页链接上添加esf字段
以上海为例:
首页:https://sh.fang.com/
新房:https://sh.newhouse....
第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容— 编写spiders爬虫文件循环抓取内容Request()方法,将指定的url地址添加到下载器下载页面,两个必须参数, 参数: url=‘url‘ callback=页面处理函数 使用时需要yield Request() parse.urljoin()方法,是urllib库下的方法,是自动url拼接,如果第二个参数的url地址是相对路径会自动与第一个参数拼接# -*- coding: utf-...
1、如何将一个scrapy爬虫项目修改成为一个简单的分布式爬虫项目官方文档:https://scrapy-redis.readthedocs.io/en/stable/只用修改scrapy项目的两个文件就可以了一个是爬虫组件文件:# -*- coding: utf-8 -*-import scrapy
from scrapy_redis.spiders import RedisSpider# 自定义爬虫类的继承类不再是scrapy.spiders下面的爬虫类,
# 而是scrapy-redis.spiders下面的爬虫类class DistributedSpiderSpider(RedisSpider):name = ‘d...
目录理论scrapy-redis架构scrapy - redis安装与使用安装scrapy-redis使用scrapy-redis的example来修改tree查看项目目录修改settings.py查看pipeline.py流程分布式爬取案例理论我们大多时候玩的爬虫都是运行在自己的机子之前我们为了提高爬虫的效率说过多进程相关的什么是分布式?你开发一个网站想要给别人访问就需要把网站部署到服务器当网站用户增多的时候一个服务器就不满足需求了于是就会把网站部署到多个服务器上这种情况通常叫...
概念:我们需要搭建一个分布式的集群,让其对一组资源进行分布联合爬取作用:提升爬取数据的效率 如何实现分布式:安装一个scrapy-redis的组件原生的scrapy是不可以实现分布式爬虫的,必须要让scrapy结合着scrapy-redis组件一起实现分布式爬虫scrapy-redis组件作用:可以给原生的scrapy框架提供可以被共享的管道和调度器 实现流程:创建一个工程创建一个基于CrawlSpider的爬虫文件修改当前的爬虫文件导包:from scrapy_redis.spide...
【项目愿景】系统基于智能爬虫方向对数据由原来的被动整理到未来的主动进攻的转变的背景下,将赋予”爬虫”自我认知能力,去主动寻找”进攻”目标。取代人工复杂而又单调的重复性工作。能够实现在人工智能领域的某一方向上独当一面的作用。【项目进展】项目一期基本实现框架搭建,对数据的处理和简单爬取任务实现。【项目说明】为了能够更好理解优秀框架的实现原理,本项目尽量屏蔽优秀开源第三方jar包实现,自定义实现后再去择优而...
前面我们讲到的elasticsearch(搜索引擎)操作,如:增、删、改、查等操作都是用的elasticsearch的语言命令,就像sql命令一样,当然elasticsearch官方也提供了一个python操作elasticsearch(搜索引擎)的接口包,就像sqlalchemy操作数据库一样的ORM框,这样我们操作elasticsearch就不用写命令了,用elasticsearch-dsl-py这个模块来操作,也就是用python的方式操作一个类即可 elasticsearch-dsl-py下载下载地址:https://github.com/ela...
CrawlSpiderCrawlSpider:
问题:如果我们想要对某一个网站的全站数据进行爬取?
解决方案:
1. 手动请求的发送
2. CrawlSpider(推荐)之前的事基于Spider类CrawlSpider概念:CrawlSpider其实就是Spider的一个子类。CrawlSpider功能更加强大(链接提取器,规则解析器)。代码:
1. 创建一个基于CrawlSpider的爬虫文件
a) scrapy genspider –t crawl 爬虫名称 起始url-------scrapy.spiders.CrawlSpider创建项目:sc...
大家好, QQ 群 里的 网友 提议 搞一个 分布式爬虫调度项目,所以发起了这个项目 。 DSpiders, D 表示 “分布式”(Distributed) , Spiders 取 复数 表示 很多 的 小爬虫,爬呀爬 …… 很可爱 …… 原文:https://www.cnblogs.com/KSongKing/p/10987327.html
如果用服务端爬虫会遇到各种问题,如何实现访客打开网页时用访客的ip访问被爬的网站,然后把资料上传,这样可以实现分布式爬虫吗?ajax获取被爬的资料然后传到自己的服务器?
是否已有类似的例子或者开源项目?回复内容:如果用服务端爬虫会遇到各种问题,如何实现访客打开网页时用访客的ip访问被爬的网站,然后把资料上传,这样可以实现分布式爬虫吗?ajax获取被爬的资料然后传到自己的服务器?
是否已有类似的例子或者开源项目?...
python视频教程栏目介绍分布式爬虫原理。免费推荐:python视频教程首先,我们先来看看,如果是人正常的行为,是如何获取网页内容的。(1)打开浏览器,输入URL,打开源网页(2)选取我们想要的内容,包括标题,作者,摘要,正文等信息(3)存储到硬盘中上面的三个过程,映射到技术层面上,其实就是:网络请求,抓取结构化数据,数据存储。我们使用Python写一个简单的程序,实现上面的简单抓取功能。#!/usr/bin/python
#-*- coding: utf-...
python视频教程栏目介绍分布式爬虫原理。免费推荐:python视频教程首先,我们先来看看,如果是人正常的行为,是如何获取网页内容的。(1)打开浏览器,输入URL,打开源网页(2)选取我们想要的内容,包括标题,作者,摘要,正文等信息(3)存储到硬盘中上面的三个过程,映射到技术层面上,其实就是:网络请求,抓取结构化数据,数据存储。我们使用Python写一个简单的程序,实现上面的简单抓取功能。#!/usr/bin/python
#-*- coding: utf-...
1.1打开浏览器,访问redist官网https://redis.io/download 1.2如图所示:点击windows目录下的learn morn进入github下载界面1.3如下图所示:点击clone or download下载源码压缩包
2.redis的安装及验证
2.1解压及安装过程省略,安装后目录 各文件的含义文件名
简要redis-benchmark.exe
基准测试redis-check-aof.exe
aofredischeck-dump.exe
dumpredis-cli.exe
客户端redis-server.exe
服务器redis.windows.conf
配置文件
...