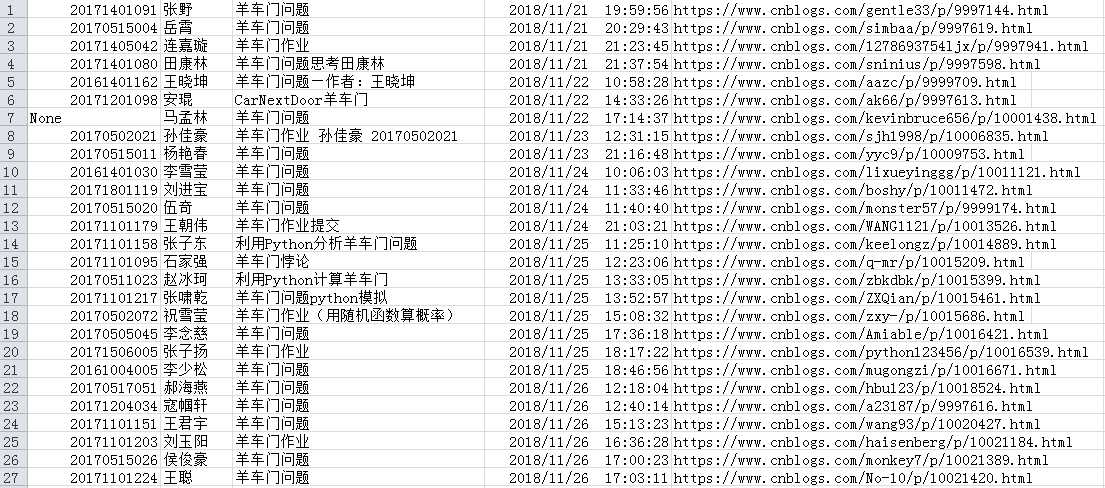
请分析作业页面,爬取已提交作业信息,并生成已提交作业名单,保存为英文逗号分隔的csv文件。文件名为:hwlist.csv 。 文件内容范例如下形式: 学号,姓名,作业标题,作业提交时间,作业URL20194010101,张三,羊车门作业,2018-11-13 23:47:36.8,http://www.cnblogs.com/sninius/p/12345678.html20194010102,李四,羊车门,2018-11-14 9:38:27.03,http://www.cnblogs.com/sninius/p/87654321.html *注1:如制作定期爬去作业爬虫,请注意爬...
前言: 最近被网络爬虫中的去重策略所困扰。使用一些其他的“理想”的去重策略,不过在运行过程中总是会不太听话。不过当我发现了BloomFilter这个东西的时候,的确,这里是我目前找到的最靠谱的一种方法。 如果,你说URL去重嘛,有什么难的。那么你可以看完下面的一些问题再说这句话。关于BloomFilter: Bloom filter 是由 Howard Bloom 在 1970 年提出的二进制向量数据结构,它具有很好的空间和时间效率,被用来检测一个元素是...
今天尝试使用python写一个网络爬虫代码,主要是想访问某个网站,从中选取感兴趣的信息,并将信息按照一定的格式保存早Excel中。此代码中主要使用到了python的以下几个功能,由于对python不熟悉,把代码也粘贴在下面。1, 使用url打开网站网页import urllib2data = urllib2.urlopen(string_full_link).read().decode('utf8')print data
2,使用正则表达式匹配
import re#一般的英文匹配
reg = """a href=\S* target='_blank' title=...
网络爬虫之requests模块今日概要基于requests的get请求基于requests模块的post请求基于requests模块ajax的get请求基于requests模块ajax的post请求综合项目练习:爬取国家药品监督管理总局中基于中华人民共和国化妆品生产许可证相关数据知识点回顾常见的请求头常见的相应头https协议的加密方式
基于如下5点展开requests模块的学习什么是requests模块requests模块是python中原生的基于网络请求的模块,其主要作用是用来模拟浏览器发起...
Python中可以用来爬取网络数据的库有很多,常见的有:urllib、urllib2、urllib3、requests、scrapy、selenium等。 基本上可以分为3类: 第一类:urllib、urllib2、urllib3、requests; 第二类:scrapy; 第三类:selenium; 第一类是python自带的库,其中requests上手简单,功能强大,缺点就是缺少配套工程,自己需要自己写不少的代码处理语料(哈哈,urllib、urllib2、urllib3不建议...
前几天给大家分享了利用Python网络爬虫抓取微信朋友圈的动态(上)和利用Python网络爬虫爬取微信朋友圈动态——附代码(下),并且对抓取到的数据进行了Python词云和wordart可视化,感兴趣的伙伴可以戳这篇文章:利用Python词云和wordart可视化工具对朋友圈数据进行可视化。今天我们继续focus on微信,不过这次给大家带来的是利用Python网络爬虫抓取微信好友总数量和微信好友男女性别的分布情况。代码实现蛮简单的,具体的教程如下...
前几天,被老板拉去说要我去抓取大众点评某家店的数据,当然被我义正言辞的拒绝了,理由是我不会。。。但我的反抗并没有什么卵用,所以还是乖乖去查资料,因为我是从事php工作的,首先找的就是php的网络爬虫源码,在我的不懈努力下,终于找到phpspider,打开phpspider开发文档首页我就被震惊了,标题《我用爬虫一天时间“偷了”知乎一百万用户,只为证明PHP是世界上最好的语言 》,果然和我预料的一样,php就是世界上最好的语言。废...
在爬取网站之前,要做以下几项工作 1.下载并检查 网站的robots.txt文件 ,让爬虫了解该网站爬取时有哪些限制。2.检查网站地图 3.估算网站大小利用百度或者谷歌搜索 Site:example.webscraping.com 结果如下 找到相关结果数约5个 数字为估算值。网站管理员如需了解更准确的索引量 4.识别网站所使用的技术使用python 中的builtwith 模块 下载地址https://pypi.python.org/pypi/python-builtwith 运行 pip install builtuith 安装完...
Python:requests库、BeautifulSoup4库的基本使用(实现简单的网络爬虫)一、requests库的基本使用requests是python语言编写的简单易用的HTTP库,使用起来比urllib更加简洁方便。 requests是第三方库,使用前需要通过pip安装。pip install requests 1.基本用法:import requests#以百度首页为例
response = requests.get(‘http://www.baidu.com‘)#response对象的属性print(response.status_code) # 打印状态码print(response.url...
平时没事喜欢看看freebuf的文章,今天在看文章的时候,无线网总是时断时续,于是自己心血来潮就动手写了这个网络爬虫,将页面保存下来方便查看 先分析网站内容,红色部分即是网站文章内容div,可以看到,每一页有15篇文章随便打开一个div来看,可以看到,蓝色部分除了一个文章标题以外没有什么有用的信息,而注意红色部分我勾画出的地方,可以知道,它是指向文章的地址的超链接,那么爬虫只要捕捉到这个地址就可以了。接下来在一个...
今天终于把脚本弄好了,虽然是东拼西凑的,总算有点成就感啦,下面把代码帖这~package studyjava;import java.io.BufferedReader;
import java.io.File;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java...
本次实战项目适合,有一定Python语法知识的小白学员。本人也是根据一些网上的资料,自己摸索编写的内容。有不明白的童鞋,欢迎提问。 目的:爬取百度小说吧中的原创小说《猎奇师》部分小说内容链接:http://tieba.baidu.com/p/4792877734 首先,自己定义一个类,方便使用。其实类就像一个“水果篮”,这个“水果篮”里有很多的“水果”,也就是我们类里面定义的变量啊,函数啊等等,各种各样的。每一种"水果"都有自己的独特的口味,...
第一部分: 请分析作业页面,爬取已提交作业信息,并生成已提交作业名单,保存为英文逗号分隔的csv文件。文件名为:hwlist.csv 。 文件内容范例如下形式: 学号,姓名,作业标题,作业提交时间,作业URL20194010101,张三,羊车门作业,2018-11-13 23:47:36.8,http://www.cnblogs.com/sninius/p/12345678.html20194010102,李四,羊车门,2018-11-14 9:38:27.03,http://www.cnblogs.com/sninius/p/87654321.html *注1:如制作定期爬去作业爬虫...
代码如下package Game;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class Main {public static void main(String[] args) throws IOException {File file=new File("D:\\index.html");BufferedReader buf=new BufferedReader(new InputStreamR...
人力资源部漂亮的小MM,跑来问我:老陈,数据分析和爬虫究竟是关系呀?说实在的,我真不想理她,因为我一直认为这个跟她的工作关系不大,可一想到她负责我负责部门的招聘工作,我只好勉为其难地跟她说:数据分析,吃里,爬虫,爬外,合在一起就是吃里爬外。大数据时代,要想进行数据分析,首先要有数据来源,单靠公司那几条毛毛雨(数据),分析个寂寞都不够,唯有通过学习爬虫,从外部(网站)爬取一些相关、有用的数据,才能让老板进...