tensorflow2.0学习(2)----线性回归和分类
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了tensorflow2.0学习(2)----线性回归和分类,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含1496字,纯文字阅读大概需要3分钟。
内容图文
来自《TensorFlow深度学习》书籍
一、线性回归
model = tf.keras.Sequential() #序列模型,在此基础上搭网络
model.add(tf.keras.layers.Dense(1,input_shape = (1,))) #全连接层
model.summary()

二、分类
import
os
import
tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, optimizers, datasets
加载数据
x的大小(60000,28,28),60000个样本,每个样本由28行、28列构成,数值大小为【0,255】
y大小为(60000),代表标签数字,0~9
#
load_data()函数返回两个元祖(tuple)对象,第一个是训练集,第二个是测试集。
(x, y) , (x_val, y_val) = datasets.mnist.load_data()
x = 2 * tf.convert_to_tensor(x, dtype=tf.float32) / 255. - 1
y = tf.convert_to_tensor(y, dtype=tf.int32) #转换成整形张量print(x.shape, y.shape)
train_dataset = tf.data.Dataset.from_tensor_slices((x,y)) #构建数据集对象
train_dataset = train_dataset.batch(512) #批量训练
模型
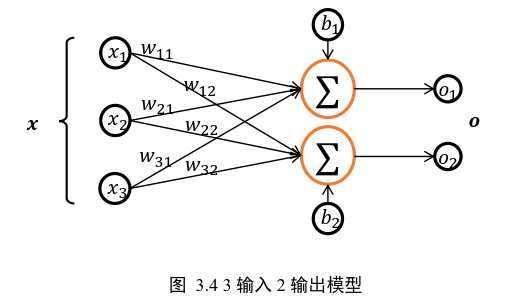
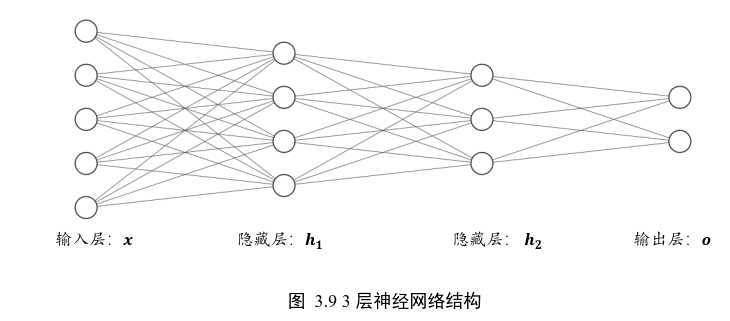
model = keras.Sequential([ layers.Dense(256, activation = ‘relu‘), #隐藏层1 layers.Dense(128, activation = ‘relu‘), #隐藏层2 layers.Dense(10) #输出层,输出节点数为10 ])
训练
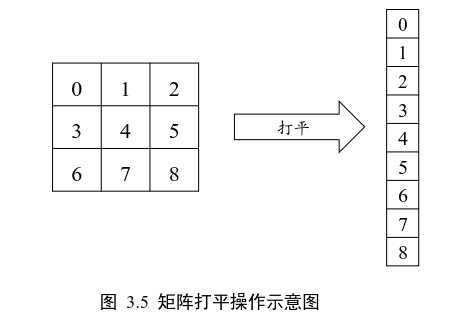
with tf.GradientTape() as tape: #构建梯度记录环境 x = tf.reshape(x, (-1,28*28)) #打平操作,[b,28,28] => [b,284] out = model(x) #计算输出预测结果 [b,784] => [b ,10] y_onehot = tf.one_hot(y,depth=10) #[b] => [b,10] loss = tf.square(out - y_onehot) #计算差的平方和, [b,10] loss = tf.reduce_sum(loss) / x.shape[0] #计算每个样本的平均误差, [b]#自动求导函数求出所有参数的梯度信息,计算梯度w1, w2, w3, b1 ,b2 , b3 grads = tape.gradient(loss, model.trainable_variables) optimizer=optimizers.SGD(learning_rate=0.001) #更新网络参数,w ‘= w - lr * grad optimizer.apply_gradients(zip(grads,model.trainable_variables))
原文:https://www.cnblogs.com/Lee-yl/p/12554925.html
内容总结
以上是互联网集市为您收集整理的tensorflow2.0学习(2)----线性回归和分类全部内容,希望文章能够帮你解决tensorflow2.0学习(2)----线性回归和分类所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。