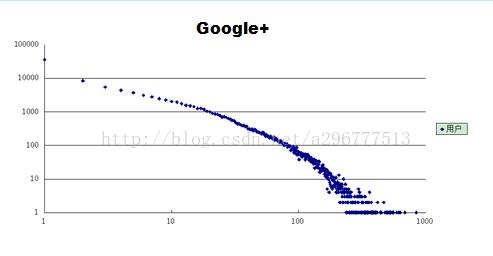
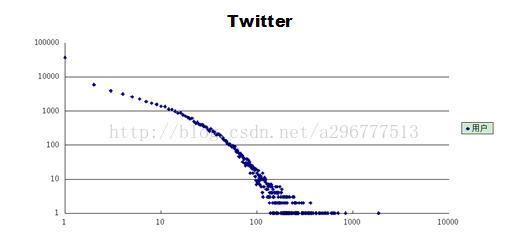
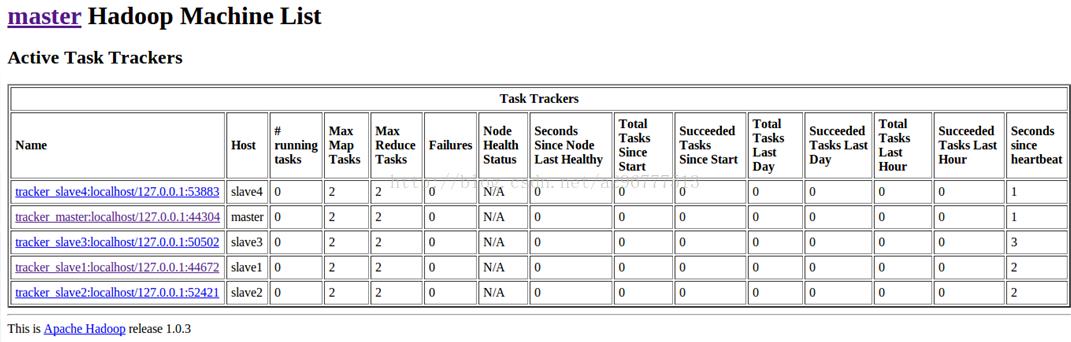
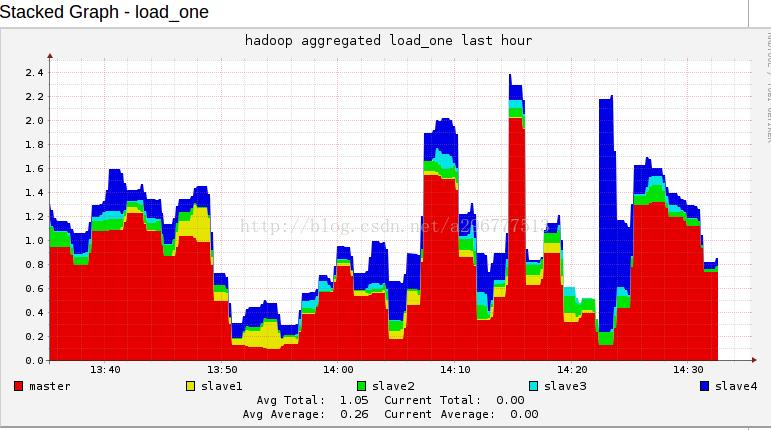
昨天终于hadoop的项目验收完成了,终于可以松一口气了,总体还是比较满意的。首先说一下项目流程,用mapreduce对数据进行预处理,然后用mahout中的聚类算法(kmeans)对数据进行处理,最后用peoplerank对数据进行处理。根据老师交给我们的数据,包括Google+和Twitter的部分社交网络数据。以下是两个数据下载的链接http://snap.stanford.edu/data/egonets-Gplus.html(Google+)http://snap.stanford.edu/data/egonets-Twitter.html...
接下来我们按照MapReduce过程中数据流动的顺序,来分解org.apache.hadoop.mapreduce.lib.*的相关内容,并介绍对应的基类的功能。首先是input部分,它实现了MapReduce的数据输入部分。类图如下:650) this.width=650;" src="/upload/getfiles/default/2022/11/15/20221115031623971.jpg" width="600" /> 类图的右上角是InputFormat,它描述了一个MapReduceJob的输入,通过InputFormat,Hadoop可以:l 检查MapReduce输入数...
MapReduce的设计思想主要的思想是分而治之(divide and conquer),分治算法。将一个大的问题切分成很多小的问题,然后在集群中的各个节点上执行,这既是Map过程。在Map过程结束之后,会有一个Ruduce的过程,这个过程即将所有的Map阶段产出的结果进行汇集。写MapReduce程序的步骤:1.把问题转化为MapReduce模型2.设置运行的参数3.写map类4.写reduce类例子:统计单词个数将文件拆分成splits,每个文件为一个split,并将文件按行分割形成...
数据处理与联机分析处理 ( OLAP )
联机分析处理是那些为了支持商业智能,报表和数据挖掘与探索等业务而开展的工作。这类工作的例子有零售商按地区和季度两个维度计算门店销售额,银行按语言和月份两个维度计算手机银行装机量,设备制造商定位有哪些零部件的故障率比期望值高,以及医院研究有哪些事件会引起高危婴儿紧张等。
如果原始数据来源于 OLTP 系统,典型的做法是将这些数据拷贝到 OLAP 数据库中,再进行这类...
网站日志分析项目案例(一)项目介绍:http://www.cnblogs.com/edisonchou/p/4449082.html网站日志分析项目案例(二)数据清洗:http://www.cnblogs.com/edisonchou/p/4458219.html一、数据情况分析1.1 数据情况回顾 该论坛数据有两部分: (1)历史数据约56GB,统计到2012-05-29。这也说明,在2012-05-29之前,日志文件都在一个文件里边,采用了追加写入的方式。 (2)自2013-05-30起,每天生成一个数据文件,约150MB左右...
原文:http://crxy2016.iteye.com/blog/2209413
本文由 网易云 发布。 Kudu是Cloudera开源的新型列式存储系统,是Apache Hadoop生态圈的新成员之一(incuba ng),专门为了对快速变化的数据进行快速的分析,填补了以往Hadoop存储层的空缺。本文主要对Kudu的动机、背景,以及架构进行简单介绍。背景——功能上的空白 Hadoop生态系统有很多组件,每一个组件有不同的功能。在现实场景中,用户往往需要同时部署很多Hadoop工具来解决同一个问题,这种架构称为混合架构 (hybrid ...
向Hadoop集群提交作业时,需要指定作业输入的格式(未指定时默认的输入格式为TextInputFormat)。在Hadoop中使用InputFormat类或InputFormat接口描述MapReduce作业输入的规范或者格式,之所以说InputFormat类或InputFormat接口是因为在旧的API(hadoop-0.x)中InputFormat被定义为接口,而在新的API(hadoop-1.x及hadoop-2.x)中,InputFormat是做为抽象类存在的,在本篇文章中主要讲述InputFormat抽象类及其子类。InputFormat主要...
系列前三篇文章中介绍了分布式存储和计算系统Hadoop以及Hadoop集群的搭建、Zookeeper集群搭建、HBase分布式部署等。当Hadoop集群的数量达到1000+时,集群自身的信息将会大量增加。Apache开发出一个开源的数据收集和分析系统—Chukwa来处理Hadoop集群的数据。Chukwa有几个非常吸引人的特点:它架构清晰,部署简单;收集的数据类型广泛,具有很强的扩展性;与 Hadoop 无缝集成,能完成海量数据的收集与整理。1 Chukwa简介 在Chukw...
1.概况 截至目前,Apache Hadoop版本分为两代,我们将第一代Hadoop称为Hadoop 1.0,第二代Hadoop称为Hadoop 2.0。前者主要有如下几种实现方式:1)社区版本基于Secondary namenode机制来定时备份HDFS metadata元数据信息;2)Avatar在Secondarynamenode的基础上实现了基于NFS共享存储方式的热备方案。3)Backup Node通过提供备用节点同步Namenode中的Matadata数据实现。后者基于NFS或者Journalnode实现HA同步两个namenode节...
在上一篇使用hadoop mapreduce分析mongodb数据:(1)中,介绍了如何使用Hadoop MapReduce连接MongoDB数据库以及如何处理数据库,本文结合一个案例来进一步说明Hadoop MapReduce处理MongoDB的细节原始数据> db.stackin.find({})
{ "_id" : ObjectId("575ce909aa02c3b21f1be0bb"), "summary" : "good good day", "url" : "url_1" }
{ "_id" : ObjectId("575ce909aa02c3b21f1be0bc"), "summary" : "hello world good world", "url"...
前言在做需求时,经常遇到多个目录,也就是多个维度进行join,这里分析一下,数据是怎么流动的。1、多目录输入使用MultipleInputs.addInputPath() 对多目录制定格式和map2、数据流分析map按行读入数据,需要对不同的输入目录,打上不同的标记(这个方法又叫reduce端连接),map在输出后会进行partition和sort,按照key进行排序,然后输出到reduce进行处理。例子三个输入文件:a.txt:500
501
b.txt:500 501
600 505
c.txt:501 500...
NameNodeHttpServer启动源码剖析,这一部分主要按以下步骤进行: 一、源码调用分析 二、伪代码调用流程梳理 三、http server服务流程图解第一步,源码调用分析 前一篇文章已经锁定到了NameNode.java类文件,搜索找到main(),可以看到代码只有寥寥几行,再筛除掉一些参数校验以及try-catch逻辑代码, 剩下的核心的代码甚至只有两行,如下: 1publicstaticvoid main(String argv[]) throws Exception {2if (DFSUtil.p...
1.概述本课程的视频教程地址:《Hadoop 回顾》 如果本教程能帮助到您,希望您能点击进去观看一下,而且现在注册成为极客学院的会员,验证手机号码和邮箱号码会赠送三天的会员时间,手机端首次也可以领取五天的会员时间哦(即使是购买年会员目前也仅仅是年费260),成为极客学院学习会员可以无限制的下载和观看所有的学院网站的视频,谢谢您的支持! 好的,下面就开始本篇教程的内容分享,本篇教程我为大家介绍我们要做一个什...
好了,让我们先来看看RPC的基础Server类的具体实现,很多设计思想和实践方式值的学习。重点不是看过源码,而是从源码中学习到了什么。尤其是其中,wait和notify的使用很好的学习范例,当然还有反射...Server start()方法是入口类,基本线程都是Daemon方式让我们来看看run里面执行了什么,主要是建立socket读取客户度请求。并将客户度请求并封装为call放入队列,提醒消费者使用。下面就是Handler,主要是处理,connection接受的对象...