如何编写Python程序爬取新浪军事论坛?
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了如何编写Python程序爬取新浪军事论坛?,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2154字,纯文字阅读大概需要4分钟。
内容图文

回复内容:
context_re = r'<div.*?class=\"cont f14\".*?id=\"(.*?)\">(.*?)你准备的这个正则表达式啊,truncated!断在了
'
这里,所以只能爬第一段。
爬取新浪军事论坛需要做三件事:
一、
上CSDN汪海老师的专栏,http://blog.csdn.net/column/details/why-bug.html,学习一个。

二、
按F12看一下前端。
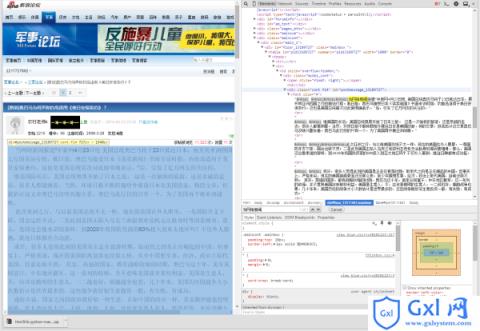
三、
from bs4 import BeautifulSoup
import requests
response = requests.get("http://club.mil.news.sina.com.cn/thread-666013-1-1.html?retcode=0") #硬点网址
response.encoding = 'gb18030' #中文编码
soup = BeautifulSoup(response.text, 'html.parser') #构建BeautifulSoup对象
divs = soup('div', 'mainbox')
#每个楼层
for div in divs:
comments = div.find_all('div','cont f14') #每个楼层的正文
with open('Sina_Military_Club.txt','a') as f:
f.write('\n'+str(comments)+'\n')
具体的编程问题就不回答了,跟用什么语言写代码无关,关键是你要分析好这个页面的html代码结构,写出合适的正则表达式来进行匹配,如果想简化的话,可以进行分次匹配(比如先得到<div class="class="main_l"">里面的第一个
里面的内容就是原帖的地址,然后再进一步处理)
大数据分析就不会了,还请赐教。
https://pythonhosted.org/pyquery/
大数据分析就不会了,还请赐教。
import requests
from bs4 import BeautifulSoup
r = requests.get("http://club.mil.news.sina.com.cn/thread-666013-1-1.html")
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text)
result = soup.find(attrs={"class": "cont f14"})
print result.text
# -*- coding:utf-8 -*-
import re, requests
from bs4 import BeautifulSoup
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
url = "http://club.mil.news.sina.com.cn/viewthread.php?tid=666013&extra=page%3D1&page=1"
req = requests.get(url)
req.encoding = req.apparent_encoding
html = req.text
soup = BeautifulSoup(html)
file = open('sina_club.txt', 'w')
x = 1
for tag in soup.find_all('div', attrs = {'class': "cont f14"}):
word = tag.get_text()
line1 = "---------------评论" + str(x) + "---------------------" + "\n"
line2 = word + "\n"
line = line1 + line2
x += 1
file.write(line)
file.close()
https://pythonhosted.org/pyquery/
内容总结
以上是互联网集市为您收集整理的如何编写Python程序爬取新浪军事论坛?全部内容,希望文章能够帮你解决如何编写Python程序爬取新浪军事论坛?所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。
来源:【匿名】