机器学习算法-随机森林(Random Forest)
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了机器学习算法-随机森林(Random Forest),小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含1622字,纯文字阅读大概需要3分钟。
内容图文
")
1、随机森林算法
随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。随机森林属于机器学习的一大分支——集成学习(EnsembleLearning)方法。随机森林具有对于很多种资料,可以产生高准确度的分类器;可以处理大量的输入变数;可以在决定类别时,评估变数的重要性;可以在内部对于一般化后的误差产生不偏差的估计;对于不平衡的分类资料集来说,可以平衡误差等优点。
2、随机森林算法步骤
首先,对样本数据进行有放回的抽样,得到多个样本集。具体来讲就是每次从原来的N个训练样本中有放回地随机抽取N个样本(包括可能重复样本)。
然后,从候选的特征中随机抽取m个特征,作为当前节点下决策的备选特征,从这些特征中选择最好地划分训练样本的特征。用每个样本集作为训练样本构造决策树。单个决策树在产生样本集和确定特征后,使用CART算法计算,不剪枝。
最后,得到所需数目的决策树后,随机森林方法对这些树的输出进行投票,以得票最多的类作为随机森林的决策。
3、随机森林应用举例
案例中使用的是sklearn中集成好的库,直接调用即可。
代码:
import numpyas np
import matplotlib.pyplotas plt
from sklearn.tree import DecisionTreeRegressor
N=100
x = np.random.rand(N) * 6 - 3
x.sort()
y=0.1*x**3+np.exp(-x*x/2)+ np.random.randn(N) * 0.2
x = x.reshape(-1, 1)
x_bar=np.linspace(-3,3,50).reshape(-1,1)
y_bar=0.1*x_bar**3+np.exp(-x_bar*x_bar/2)
plt.plot(x,y,'r.')
plt.plot(x_bar,y_bar)
plt.show()
plt.plot(x,y,'r.')
x_test=np.linspace(-3,3,50).reshape(-1,1)
dt = DecisionTreeRegressor(criterion='mse')
depth=[3,6,18]
color='rgy'
for d,c in zip(depth,color):
dt.set_params(max_depth=d)
dt.fit(x,y)
y_test = dt.predict(x_test)
plt.plot(x_test,y_test,'-',color=c,linewidth=2, label='Depth=%d' % d)
plt.legend(loc='upperleft')
plt.xlabel(u'X')
plt.ylabel(u'Y')
plt.grid(b=True)
plt.show()
结果:
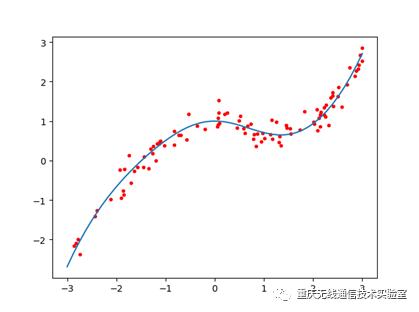
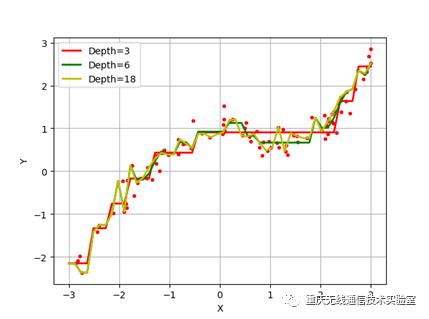
内容总结
以上是互联网集市为您收集整理的机器学习算法-随机森林(Random Forest)全部内容,希望文章能够帮你解决机器学习算法-随机森林(Random Forest)所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。