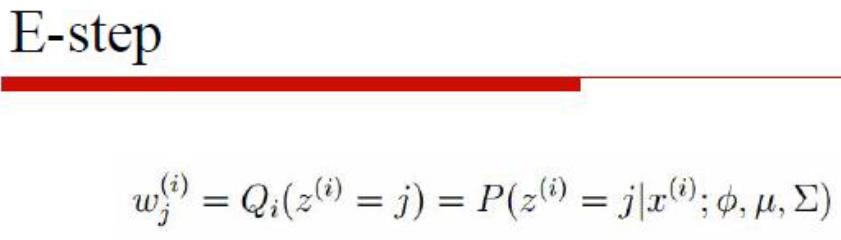最大期望算法(EM)K均值算法非常简单(可参见之前发布的博文),详细读者都可以轻松地理解它。但下面将要介绍的EM算法就要困难许多了,它与极大似然估计密切相关。1 算法原理不妨从一个例子开始我们的讨论,假设现在有100个人的身高数据,而且这100条数据是随机抽取的。一个常识性的看法是,男性身高满足一定的分布(例如正态分布),女性身高也满足一定的分布,但这两个分布的参数不同。我们现在不仅不知道男女身高分布的参数,甚...
机器学习算法汇总1. 前言通过将工作中用到的机器学习算法归纳汇总,方便以后查找,快速应用。2. 推荐算法交叉最小方差算法名字交叉最小方差, Alternating Least Squares, ALS算法描述Spark上的交替性最小二乘ALS本质是一种协同过滤的算法算法原理1. 首先将用户推荐对象交互历史转换为矩阵,行表示用户,列表示推荐对象,矩阵对应 i,j 表示用户 i 在对象 j 上有没有行为 2. 协同过滤就是要像填数独一样,填满1得到的矩阵,采用的方法...
(上接第二章) 4.3.1 KMeans 算法流程 算法的过程如下: (1)从N个数据文档随机选取K个文档作为质心 (2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类 (3)重新计算已经得到的各个类的质心 (4)迭代(2)~(3)步直至新的质心与原质心相等或者小于指定阀值,算法结束。 4.3.2 辅助函数 (1)文件数据转为矩阵:file2matrixdef file2matrix(path,delimiter):recordlist = []fp ...
1. KNN分类算法原理及应用1.1 KNN概述K最近邻(k-Nearest Neighbor,KNN)分类算法是最简单的机器学习算法。KNN算法的指导思想是“近朱者赤,近墨者黑”,由你的邻居来推断你的类型。本质上,KNN算法就是用距离来衡量样本之间的相似度。1.2 算法图示从训练集中找到和新数据最接近的k条记录,然后根据多数类来决定新数据类别算法涉及3个主要因素
1) 训练数据集2) 距离或相似度的计算衡量3) k的大小 算法描述1) 已知两类“先验...
词向量:将词语"嵌入"到一个N维空间,使得词语相近的词语放到相近的位置。机器翻译类不类似于矩阵的变换?谷歌出品的一个工具Word2Vec,用于入门。句向量?段向量?文档向量?很多事情向量化,可以解决很多问题。 传统的one-hot 编码的原来是,有多少个字就有多少个维度.科[1,0,0,0,0,0,0,0]学[0,1,0,0,0,0,0,0]one hot -- >词向量表(全连接的大矩阵)-->输出(该词的矩阵)Embedding层就是one hot 层。 时间序列:每次作预测都是一个序列...
(一)K-means提到k-means不得不说的许高建老师,他似乎比较偏爱使用这种聚类方法,在N个不同场合听到他提起过,k-means通过设置重心和移动中心两个简答的步骤,就实现了数据的聚类。下面就来介绍下k-means算法。一、 数值属性距离度量度量数值属性相似度最简单的方法就是计算不同数值间的“距离”,如果两个数值之间“距离”比较大,就可以认为他们的差异比较大,而相似度较低;换而言之,如果两数值之间“距离”较小,可认为他...
总结:量纲化(归一化,标准化)缺失值处理(补0、均值、中值、众数、自定义)编码/哑变量:忽略数字中自带数学性质(文字->数值类型)连续特征离散化(二值化/分箱处理)原文:https://www.cnblogs.com/afanti/p/10881435.html
聚类是一种无监督的学习,它将相似的对象归到同一个簇中。它有点像全自动分类(类别体系是自动构建的)。聚类方法几乎可以应用于所有对象,簇内的对象越相似,聚类的效果越好。本文要介绍一种称为K-均值(K-means)聚类的算法。之所以称之为K-均值是因为它可以发现k个不同的簇,且每个簇的中心采用簇中所含值的均值计算而成。在介绍K-均值之前,先讨论一席簇识别(cluster identification)。簇识别给出聚类结果的含义。假定有一些...
摘要:Classification And Regression Tree(CART)是一种很重要的机器学习算法,既可以用于创建分类树(Classification Tree),也可以用于创建回归树(Regression Tree),本文介绍了CART用于离散标签分类决策和连续特征回归时的原理。决策树创建过程分析了信息混乱度度量Gini指数、连续和离散特征的特殊处理、连续和离散特征共存时函数的特殊处理和后剪枝;用于回归时则介绍了回归树和模型树的原理、适用场景和创建过程。个人认为...
XGBoost原理:https://www.jianshu.com/p/7467e616f227 python实现:https://www.cnblogs.com/harekizgel/p/7683803.html 算法优势和调参:http://www.cnblogs.com/mfryf/p/6293814.html 原文:https://www.cnblogs.com/zhenpengwang/p/10898637.html
1). 扑克牌手动演练k均值聚类过程:>30张牌,3类 图1 统计表格 图2 第一轮实际情况 图3 第二轮实际情况2). *自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。(加分题)ps:之前人工智能老师教过这个算法,所以代码基本一样。源代码: # 导入数据集
from sklearn.datasets import ...
更新:文章迁移到了这里。http://lanbing510.info/2014/11/07/Neural-Network.html,有对应的PPT链接。
注:整理自向世明老师的PPT
看不到图片的同学能够直接打开链接:https://app.yinxiang.com/shard/s31/sh/61392246-7de4-40da-b2fb-ccfd4f087242/259205da4220fae3内容提要1 发展历史
2 前馈网络(单层感知器,多层感知器。径向基函数网络RBF)
3 反馈网络(Hopfield网络。联想存储网络,SOM。Boltzman及受限的玻尔兹曼机RBM,D...
老板:来了,老弟!我:来了来了。老板:今天你要去看看KNN了,然后我给你安排一个工作!我:好嘞!就是第二章吗?老板:对!去吧!可恶的老板又给我安排任务了!《机器学习实战》这本书中的第二章为我们介绍了K-近邻算法,这是本书中第一个机器学习算法,它非常有效而且易于掌握,所以可以算是入门级算法了。那我们现在就一起去学习一下!2.1 k-近邻算法概述简单的说,k-近邻算法采用测量不同特征值之间的距离进行分类。其工作原理...
1、过拟合和欠拟合怎么判断,如何解决?答:主要可以通过训练误差和测试误差入手判断是否过拟合或欠拟合。一般而言训练误差很低,但是测试误差较高,过拟合的概率较大,如果训练误差和测试误差都很高,一般是欠拟合。过拟合可以从增加样本量,减少特征数,降低模型复杂度等方面入手,实际的例子比如线性回归中,对于几十个样本的数据点就没必要用几十个变量去拟合。欠拟合则反之,需要考虑模型是否收敛,特征是否过少,模型是否过于...
版权声明: 本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleast@gmail.com 前言: 决策树这种算法有着很多良好的特性,比如说训练时间复杂度较低,预测的过程比较快速,模型容易展示(容易将得到的决策树做成图片展示出来)等。但是同时,单决策树又有一些不好的地方,比如说容易over-fitting,虽然有一些方法,如剪枝可以减少这种情况,...
")