机器学习算法篇:最大似然估计证明最小二乘法合理性
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了机器学习算法篇:最大似然估计证明最小二乘法合理性,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含5629字,纯文字阅读大概需要9分钟。
内容图文

最小二乘法的核心思想是保证所有数据误差的平方和最小,但我们是否认真思考过为什么数据误差平方和最小便会最优,本文便从最大似然估计算法的角度来推导最小二乘法的思想合理性,下面我们先了解一下最大似然估计和最小二乘法,最后我们通过中心极限定理克制的误差ε服从正态分布来引出最大似然估计和最小二乘法的关系
一、最大似然估计
先从贝叶斯公式说起:
P(W∣X)= P(X)P(X∣W)P(W)?
P(W) 先验概率,表示每个类别的概率
P(W|X) 后验概率,表示已知某事X发生的情况下,属于某个类W的概率
P(X|W) 类条件概率,在某个类W的前提下,某事X发生的概率
对于 P(W) 先验概率的估计是简单的,样本信息直接给出,但对于 P(X|W) 类条件概率来说,概率密度函数包含一个随机变量的全部信息,直接求解概率密度无法入手,因此我们将概率密度估计问题转化为参数估计问题,极大似然估计便就是一种参数估计法。
最大似然估计的核心思想是:在给出数据样本下,找出最大可能产生该样本的参数值。最大似然估计提供了一种给定观察数据来评估模型参数的方法,即模型已定,参数未知。通过最大似然估计找到能够使样本出现概率最大的参数值,则称为最大似然估计。
最大似然估计有一个重要的前提假设即:样本之间是独立同分布的,先给出一个一般模型。考虑现有一类样本集D,记作D = { x1,x2,…,xn},来估计参数 θ,有:
L(θ)= P(D∣θ)=P(x1,x2,…,xn∣θ)= i=1∏N?P(xi∣θ)
其中 P(D|θ) 既是联合概率密度函数,L(θ) 称作样本 D={x1,x2,…,xn} 关于θ的似然函数,对上式取对数可得:
l(θ)= lnL(θ)= i=1∑N?lnP(xi∣θ)
按照最大似然函数的思想,我们要求的是使得样本出现概率最大的参数θ,因此:
θ=argl(θ)
因此当 ?l(θ)/?θ = 0 成立时l(θ) 取得最大值,解此时便可得到参数 θ
注:这里的参数θ可是实数变量(一个未知参数),也可以是向量(多个未知参数)
二、最小二乘法(最小平方法)
比如我们要做数据拟合,如下图所示:
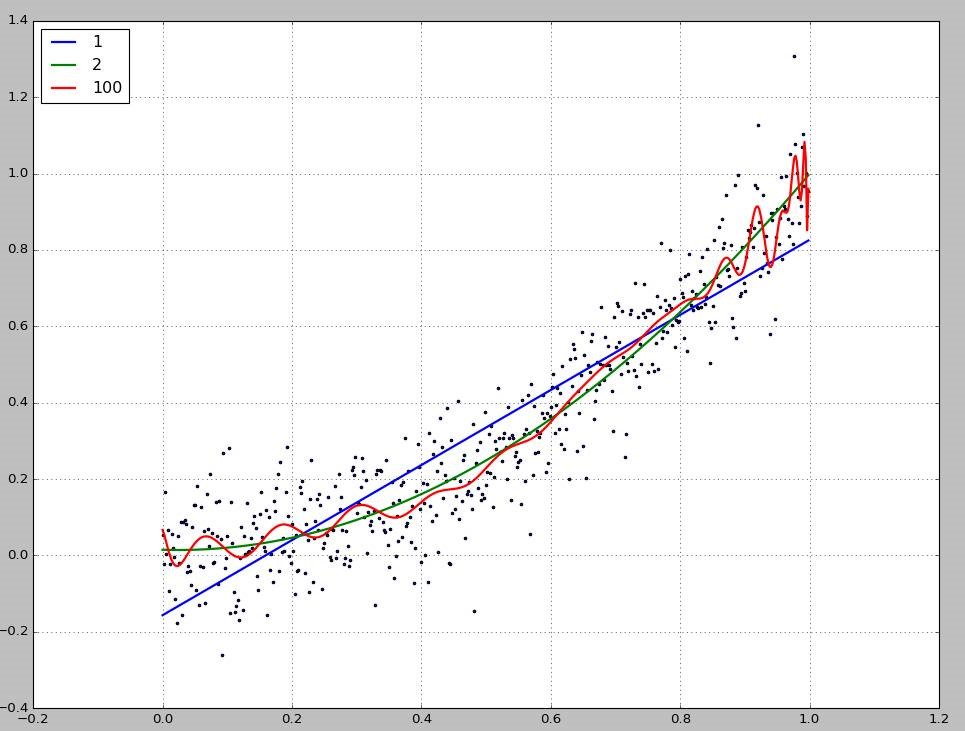
假设我们拟合函数为hθ(x),暂先不管hθ(x) 形式,拟合函数可以是线性,也可非线性,正如上图所示,现在我们需要做的便是选出拟合效果最好的函数,法国数学家勒让德定义,让数据总体误差最小的便是最好的。当然为什么勒让德如此定义我们便认为是合理的呢,下面第三节最大似然估计的角度说明该定义的合理性。
两种定义拟合总体误差:
(1) 误差绝对值之和:
i=1∑m?∣y(i)? hθ?(x(i))∣
解释:m表示样本点数,(xi, yi) 既是坐标点
(2) 误差平方和最小:
i=1∑m?( y(i)? hθ?(x(i)))2
最小二乘法便是便是采用了保证所有数据误差的平方和最小,这便是最小二乘法优化的核心思想。这里简单解释为什么不去误差绝对值之和最小,主要愿意便是误差绝对值之和最小无法转化为一个可解的寻优问题,无法确定一个合适的寻优的参数估计方程,数学上不易处理。
根据拟合函数 hθ(x) 定义形式的不同,参数的个数和形式也不同,但参数求解方式相同,都是通过对参数求偏导求解,这里以简单的线性拟合为例作简单说明,则:
hθ?(x)= a?x+b θ=[a, b]
优化方程为:
J(θ)= i=1∑m?(y(i)? (a?x(i)+b))2
对参数a,b求偏导有:
?a?J?=?2i=1∑m?x(i)(y(i) (a?x(i)+b))
?b?J?=2i=1∑m?(y(i) (a?x(i)+b))
联合上述式子便可求得参数a, b得到最优拟合函数
三、高斯正态分布、最大似然估计、最小二乘法关系
继续以上述数据拟合为例,对每个数据点拟合都会存在误差,我们定义误差为:
ε(i)= y(i)? hθ?(x(i))
假设当样本数据量足够多的情况下,我们由中心极限定理克制可知误差ε服从正态分布
即ε~N(0, σ2),因此有:
P(ε(i))= 2π?σ1?exp(?2σ2(εi)2?)
因此我们可得yi 关于xi 的概率密度公式为:
P(y(i)∣x(i);θ)= 2π?σ1?exp(?2σ2( y(i)? hθ?(x(i)))2?)
求概率密度问题是不是有想到了最大似然法,这里便可以把求概率密度转化为求参数,因此有最大似然法可得:
L(θ)= P(y∣x;θ)= i=1∏m?2π?σ1?exp(?2σ2( y(i)? hθ?(x(i)))2?)
按照最大似然估计接下来便通过最大化似然函数求参,但通过观察可以看出:
L(θ) <=> i=1∑m?( y(i)? hθ?(x(i)))2
右式是啥,不就是最小二乘法嘛,所以从此角度也说明了最小二乘法定义的所有数据误差的平方和最小既是最优的合理性。
内容总结
以上是互联网集市为您收集整理的机器学习算法篇:最大似然估计证明最小二乘法合理性全部内容,希望文章能够帮你解决机器学习算法篇:最大似然估计证明最小二乘法合理性所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。