python机器学习-sklearn挖掘乳腺癌细胞(四)
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了python机器学习-sklearn挖掘乳腺癌细胞(四),小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含1818字,纯文字阅读大概需要3分钟。
内容图文
")
?python机器学习-sklearn挖掘乳腺癌细胞( 博主亲自录制)
网易云观看地址
模型调参
调参是一门黑箱技术,需要经验丰富的机器学习工程师才能做到。幸运的是sklearn有调参的包,入门级学者也可尝试调参。
如果参数不多,可以手动写函数调参,如果参数太多可以用GridSearchCV调参,如果参数多的占用时间太长,可以用randomSizeCV调参,节约调参时间
GridSearchCV
如果参数太多可以用GridSearchCV调参
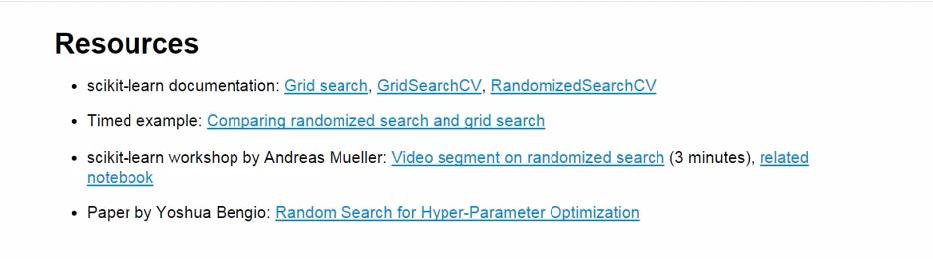
(1)单参数调参
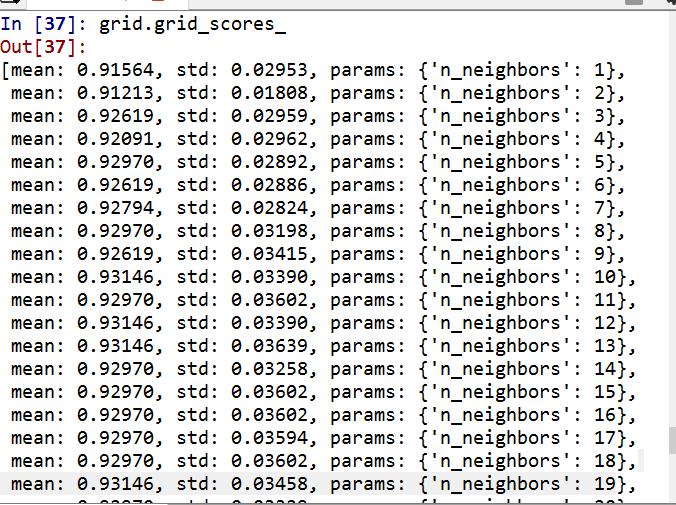
(2)多参数调参
因为有n_neighbors和weights两个参数,因此诞生了60个结果
因为有两个参数,所以得到最佳模型:weight=distance,n_neighbor=12
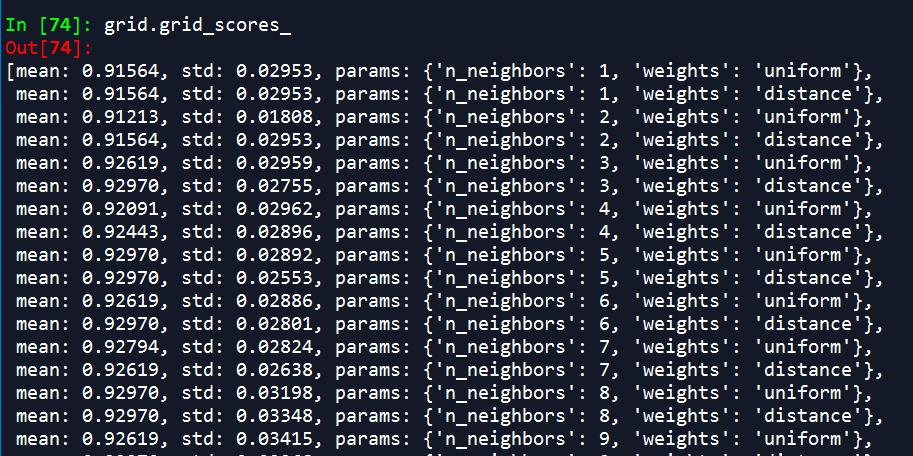
RandomSizeSearchCV
randomSizeCV调参类似于GridSearchCV的抽样
如果参数多的占用时间太长,可以用randomSizeCV调参,节约调参时间。
randomSizeCV调参准确率会略低于GridSearchCV,但可以节约大量时间。
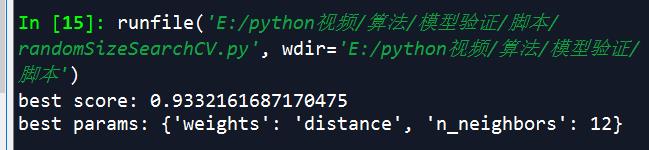
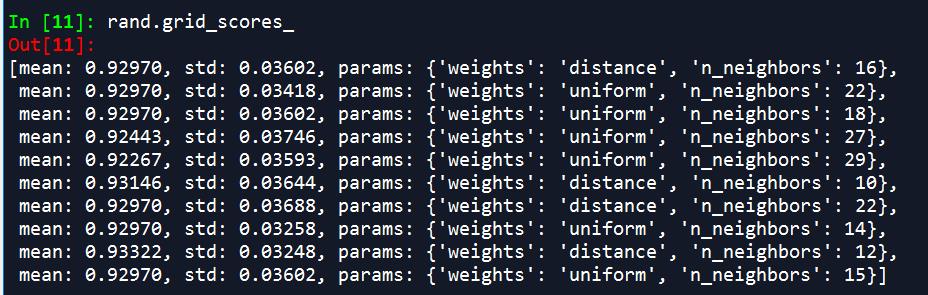
randomSizeCV调参代码
# -*- coding: utf-8 -*-
"""
Created on Sat Jun 16 19:54:25 2018
@author: 231469242@qq.com
"""
from sklearn.grid_search import RandomizedSearchCV
import matplotlib.pyplot as plt
#交叉验证
from sklearn.cross_validation import cross_val_score
from sklearn.datasets import load_breast_cancer
from sklearn.neighbors import KNeighborsClassifier
#导入数据
cancer=load_breast_cancer()
x=cancer.data
y=cancer.target
#调参knn的邻近指数n
k_range=list(range(1,31))
weight_options=['uniform','distance']
param_dist=dict(n_neighbors=k_range,weights=weight_options)
knn=KNeighborsClassifier()
#n_iter为随机生成个数
rand=RandomizedSearchCV(knn,param_dist,cv=10,scoring='accuracy',
n_iter=10,random_state=5)
rand.fit(x,y)
rand.grid_scores_
print('best score:',rand.best_score_)
print('best params:',rand.best_params_)
扫二维码,关注博主主页,学习更多Python知识

内容总结
以上是互联网集市为您收集整理的python机器学习-sklearn挖掘乳腺癌细胞(四)全部内容,希望文章能够帮你解决python机器学习-sklearn挖掘乳腺癌细胞(四)所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。