首页 / MONGODB / mongodb复制集原理
mongodb复制集原理
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了mongodb复制集原理,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2242字,纯文字阅读大概需要4分钟。
内容图文

复制集简介
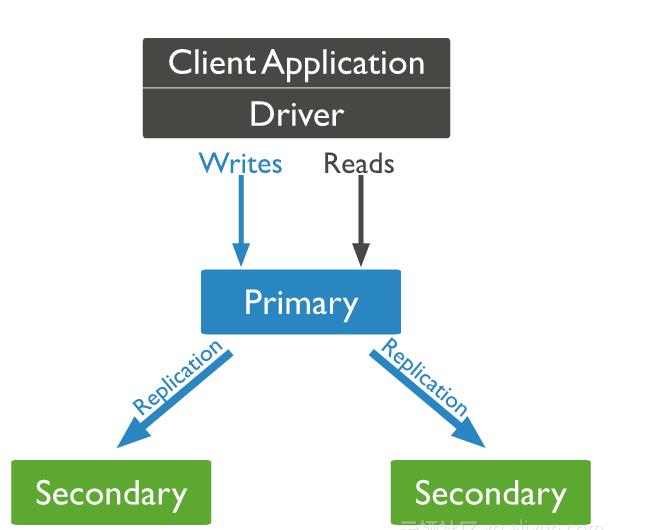
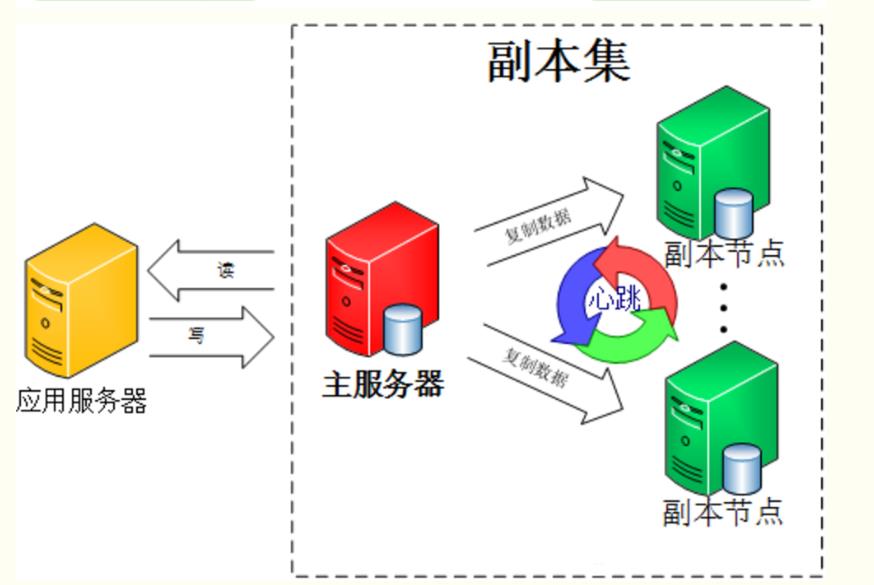
Mongodb复制集由一组Mongod实例(进程)组成,包含一个Primary节点和多个Secondary节点,Mongodb Driver(客户端)的所有数据都写入Primary,Secondary从Primary同步写入的数据,以保持复制集内所有成员存储相同的数据集,提供数据的高可用。
下图为mongodb官方的复制集,包含一个主节点和2个副本节点
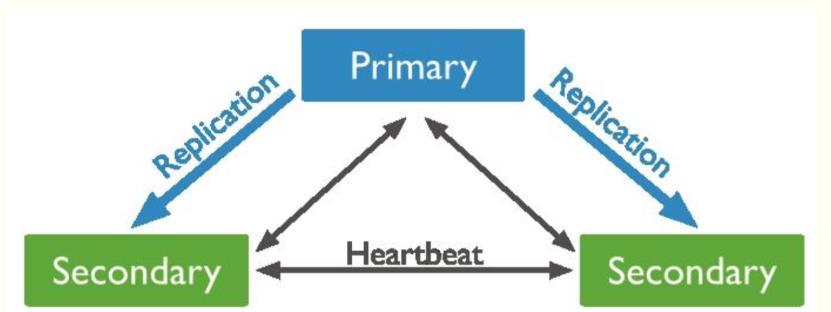
节点间心跳
复制集成员间默认每2s会发送一次心跳信息,如果10s未收到某个节点的心跳,则认为该节点已宕机;如果宕机的节点为Primary,Secondary(前提是可被选为Primary)会发起新的Primary选举。
Primary选举
复制集通过replSetInitiate命令(或mongo shell的rs.initiate())进行初始化,初始化后各个成员间开始发送心跳消息,并发起Priamry选举操作,获得『大多数』成员投票支持的节点,会成为Primary,其余节点成为Secondary
1、数据同步
Primary与Secondary之间通过oplog来同步数据,Primary上的写操作完成后,会向特殊的local.oplog.rs特殊集合写入一条oplog,Secondary不断的从Primary取新的oplog并应用。
随和数据量的不断增大,oplog也不断的增加,local.oplog.rs被设置成为了一个capped集合,当oplog的容量达到上限时,会将最旧的数据删除掉。另oplog在Secondary上可能重复应用,oplog必须具有幂等性,即重复应用也会得到相同的结果。(若有一个副本节点以外宕机,当其修复好时还要同步主节点oplog的操作,而有些操作是在它宕机之前已经同步过的,即重复的应用会得到相同的结果。)
2、capped集合
官方文档:https://docs.mongodb.com/manual/core/capped-collections/?spm=a2c4e.11153940.blogcont64.5.5aa067deKA98gi
capped集合是固定大小的集合,支持基于插入顺序插入和检索文档的高吞吐量操作。加盖的集合以类似于循环缓冲区的方式工作:一旦集合填充其分配的空间,它通过覆盖集合中最旧的文档为新文档腾出空间
Arbiter(仲裁节点)
Arbiter节点只参与投票,不能被选为Primary,并且不从Primary同步数据。
比如你部署了一个2个节点的复制集,1个Primary,1个Secondary,任意节点宕机,复制集将不能提供服务了(无法选出Primary),这时可以给复制集添加一个 Arbiter节点,即使有节点宕机,仍能选出Primary。
Arbiter本身不存储数据,是非常轻量级的服务,当复制集成员为偶数时,最好加入一个Arbiter节点,以提升复制集可用性。
节点优先级
- 每个节点都倾向于投票给优先级最高的节点
- 优先级为0的节点不会主动发起Primary选举
- 当Primary发现有优先级更高Secondary,并且该Secondary的数据落后在10s内,则Primary会主动降级,让优先级更高的Secondary有成为Primary的机会。
Optime
拥有最新optime(最近一条oplog的时间戳)的节点才能被选为主。
内容总结
以上是互联网集市为您收集整理的mongodb复制集原理全部内容,希望文章能够帮你解决mongodb复制集原理所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。