Python机器学习(Sebastian著 ) 学习笔记——第四章数据预处理(Windows Spyder Python 3.6)
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Python机器学习(Sebastian著 ) 学习笔记——第四章数据预处理(Windows Spyder Python 3.6),小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含4492字,纯文字阅读大概需要7分钟。
内容图文
 学习笔记——第四章数据预处理(Windows Spyder Python 3.6)")
数据预处理
import pandas as pd
from io import StringIO
csv_data = '''A,B,C,D
1.0,2.0,3.0,4.0
5.0,6.0,,8.0
0.0,11.0,12.0
'''
df = pd.read_csv(StringIO(csv_data)) #read_csv函数将CSV格式的数据读取到pandas的数据框DataFrame中
#StringIO函数做演示作用。如果数据来自于硬盘上的CSV文件,通过此函数以字符串的方式从文件中读取数据,并将其转换成DataFrame的格式赋值给csv_data
print (df)
#统计缺失值的数量 sum()
#isnull()返回一个布尔型的DataFrame值 DataFrame元素单元中包含数字型数值则返回False,数据值缺失则返回True,sum()得到每列中缺失值的数量
print (df.isnull().sum())
print (df.values) #通过DataFrame的value属性访问相关的NumPy数组
print (df.dropna()) #dropna()删除包含缺失值的行
print (df.dropna(axis = 1)) #axis=1 删除数据集中至少包含一个NaN值的列
print (df.dropna(how='all'))
print (df.dropna(thresh=4))
print (df.dropna(subset=['C']))
#均值插补 即使用相应的特征均值来替换缺失值 使用scikit-learn中的Impute类
from sklearn.preprocessing import Imputer
imr = Imputer(missing_values='NaN', strategy='mean', axis=0)
imr = imr.fit(df)
imputed_data = imr.transform(df.values)
print (imputed_data)
将数据集划分为训练数据集合测试数据集 本例数据集包含178个葡萄酒样本,每个样本通过13个特征
对其化学特征进行描述。
import pandas as pd
df_wine = pd.read_csv('D:\Python\data\wine.data', header=None) #本地硬盘读取数据集
#df_wine = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data', header=None) #在线读取开源的葡萄酒数据集
df_wine.columns = ['Class label', 'Alcohol',
'Malic acid', 'Ash',
'Alcalinity of ash', 'Magnesium',
'Total phenols', 'Flavanoids',
'Nonflavanoid phenols',
'Proanthocyanins',
'Color intensity', 'Hue',
'OD280/0D315 of diluted wines',
'Proline'
]
#print ('Class labels', np.unique(df_wine['Class label']))
#print (df_wine.head())数据集随机划分为测试数据集合训练数据集 使用scikit-learn下cross_validation子模块中的train_test_split函数:
from sklearn.cross_validation import train_test_split
X, y = df_wine.iloc[:, 1:].values, df_wine.iloc[:, 0].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
print (X_train, X_test, y_train, y_test)数据集随机划分为测试数据集合训练数据集 使用scikit-learn下cross_validation子模块中的train_test_split函数:
from sklearn.cross_validation import train_test_split
X, y = df_wine.iloc[:, 1:].values, df_wine.iloc[:, 0].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
#print (X_train, X_test, y_train, y_test)
特征缩放是数据预处理过程中至关重要的一步 特征值缩放到相同的区间可以使其性能更佳
#scikit-learn 最小-最大缩放
from sklearn.preprocessing import MinMaxScaler
mms = MinMaxScaler()
X_train_norm = mms.fit_transform(X_train)
X_test_norm = mms.transform(X_test)
#print (X_train_norm, X_test_norm)#scikit-learn 标准化类
from sklearn.preprocessing import StandardScaler
stdsc = StandardScaler()
X_train_std = stdsc.fit_transform(X_train)
X_test_std = stdsc.transform(X_test)
print (X_train_std, X_test_std)减少过拟合问题:正则化、特征选择降维,scikit-learn 中支持L1的正则化模型 将penalty参数设定为'l1'进行简单的数据稀疏处理
from sklearn.linear_model import LogisticRegression
LogisticRegression(penalty='l1')
lr = LogisticRegression(penalty='l1', C=0.1)
lr.fit(X_train_std, y_train)
#print ('Training accuracy:', lr.score(X_train_std, y_train))
#print ('Test accuracy:', lr.score(X_test_std, y_test)) #训练和测试精确度大于98% 显示此模型未出现过拟合。
#print (lr.intercept_) #lr.intercept_ 得到截距项后,返回三个数值的数组
#print (lr.coef_) #lr.coef_ 得到的权重数组包含三个权重系数向量绘制正则化效果图 展示将权重系数(正则化参数)应用于多个特征上时所产生的不同的正则化效果
import matplotlib.pyplot as plt
fig = plt.figure()
ax = plt.subplot(111)
colors = ['blue', 'green', 'red', 'cyan', 'magenta', 'yellow', 'black', 'pink', 'lightgreen', 'lightblue', 'gray', 'indigo', 'orange']
weights, params = [], []
for c in np.arange(-4, 6, dtype=float):
lr = LogisticRegression(penalty='l1',
C=10**c,
random_state=0)
lr.fit(X_train_std, y_train)
weights.append(lr.coef_[1])
params.append(10**c)
weights = np.array(weights)
for column, color in zip(range(weights.shape[1]), colors):
plt.plot(params, weights[:, column],
label=df_wine.columns[column+1],
color=color)
plt.axhline(0, color='black', linestyle='--', linewidth=3)
plt.xlim([10**(-5), 10**5])
plt.ylabel('weight coefficient')
plt.xlabel('C')
plt.xscale('log')
plt.legend(loc='upper left')
ax.legend(loc='upper center',
bbox_to_anchor=(1.38, 1.03),
ncol=1, fancybox=True)
plt.show()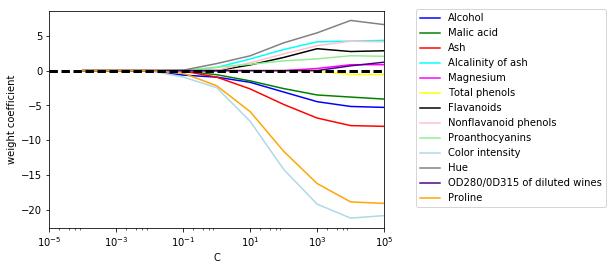
内容总结
以上是互联网集市为您收集整理的Python机器学习(Sebastian著 ) 学习笔记——第四章数据预处理(Windows Spyder Python 3.6)全部内容,希望文章能够帮你解决Python机器学习(Sebastian著 ) 学习笔记——第四章数据预处理(Windows Spyder Python 3.6)所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。