首页 / PYTHON / python爬取多网小说
python爬取多网小说
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了python爬取多网小说,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3582字,纯文字阅读大概需要6分钟。
内容图文

爬取小说完整代码在GIT中的地址:https://github.com/wenjiankui/books
CSDN代码资源下载地址:https://download.csdn.net/download/qq_39025957/14927458
一、系统环境
python3.7
pyqt5
Windows10 x64
二、讲解爬取小说过程
以爬取笔趣阁平台小说为例进行讲解,其他平台,是同一个思路
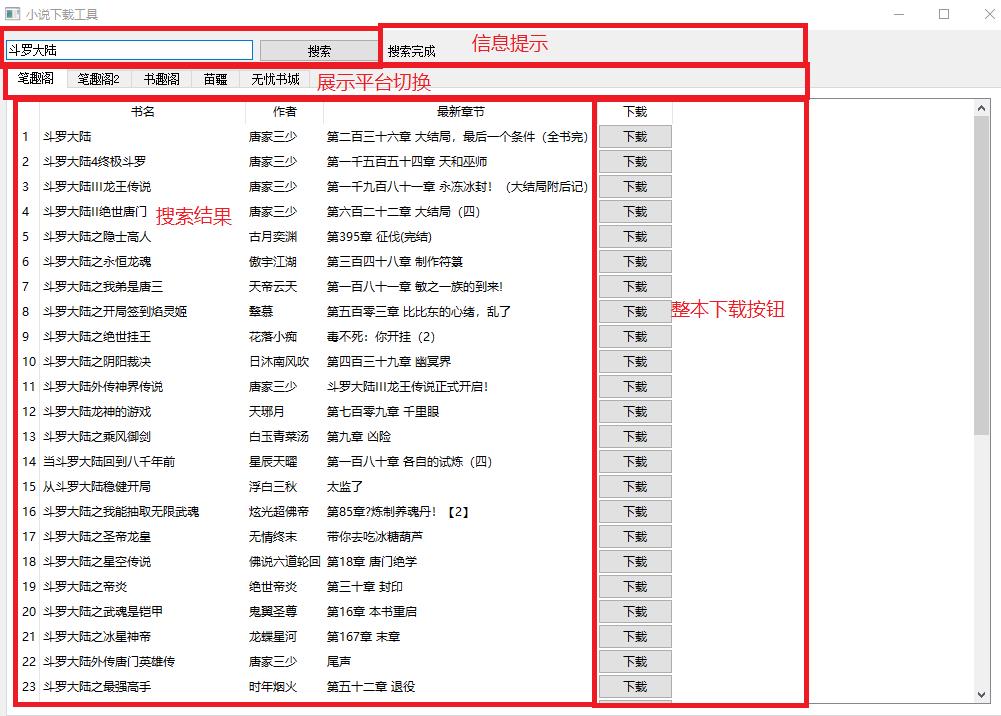
1、打开笔趣阁首页
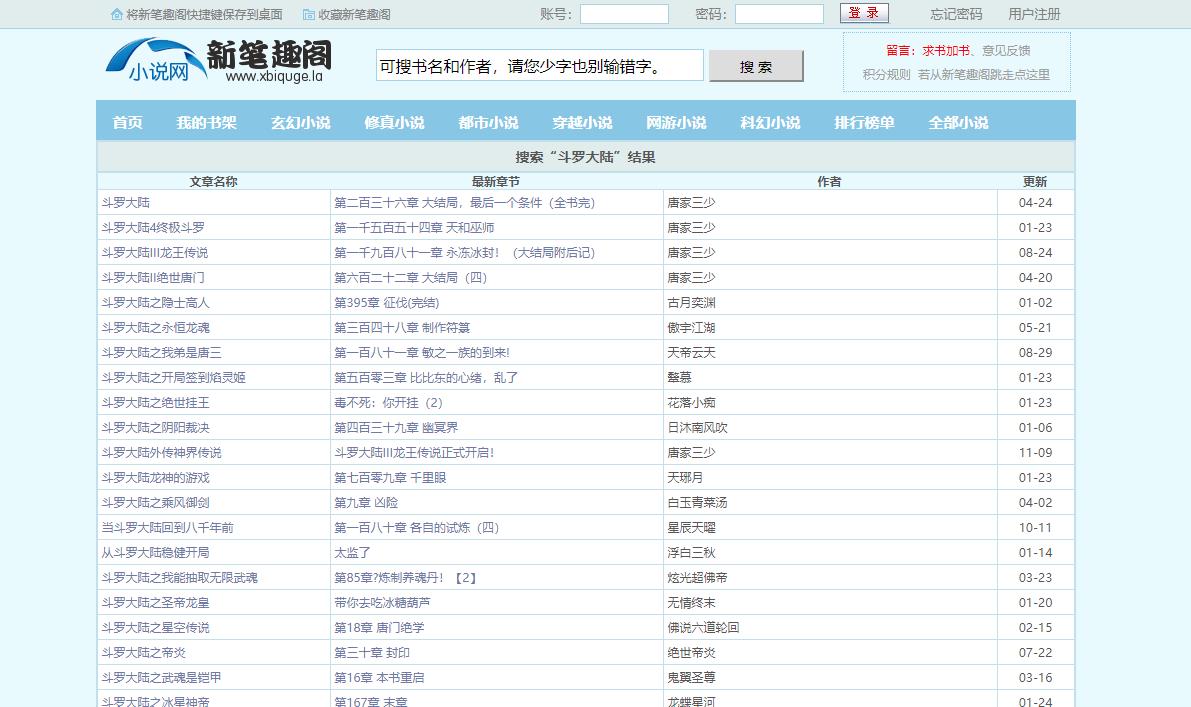
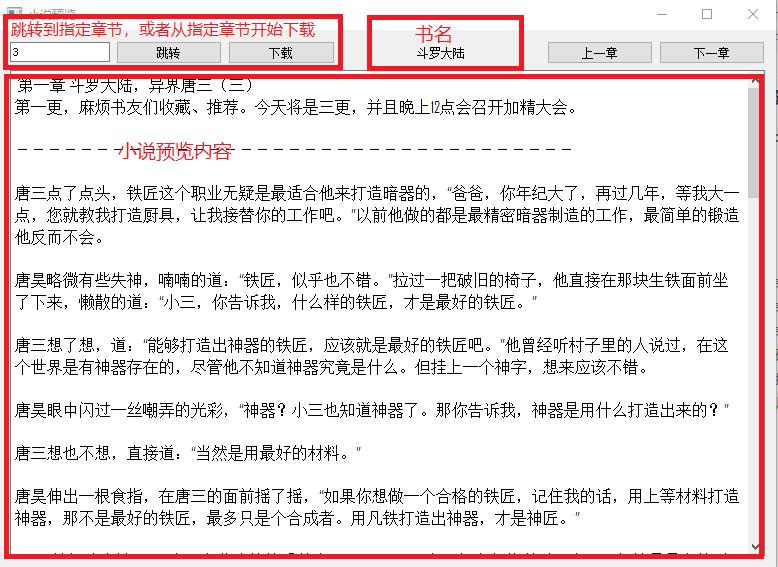
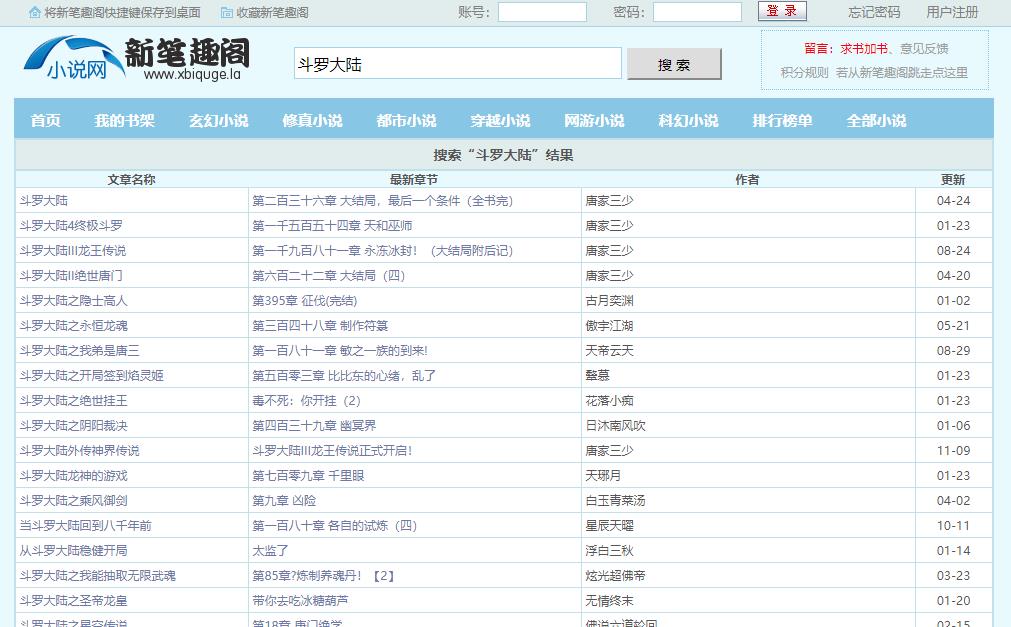
2、在搜索框输入要小说名,点击搜索,
3、按F12调出开发者工具,然后刷新网页
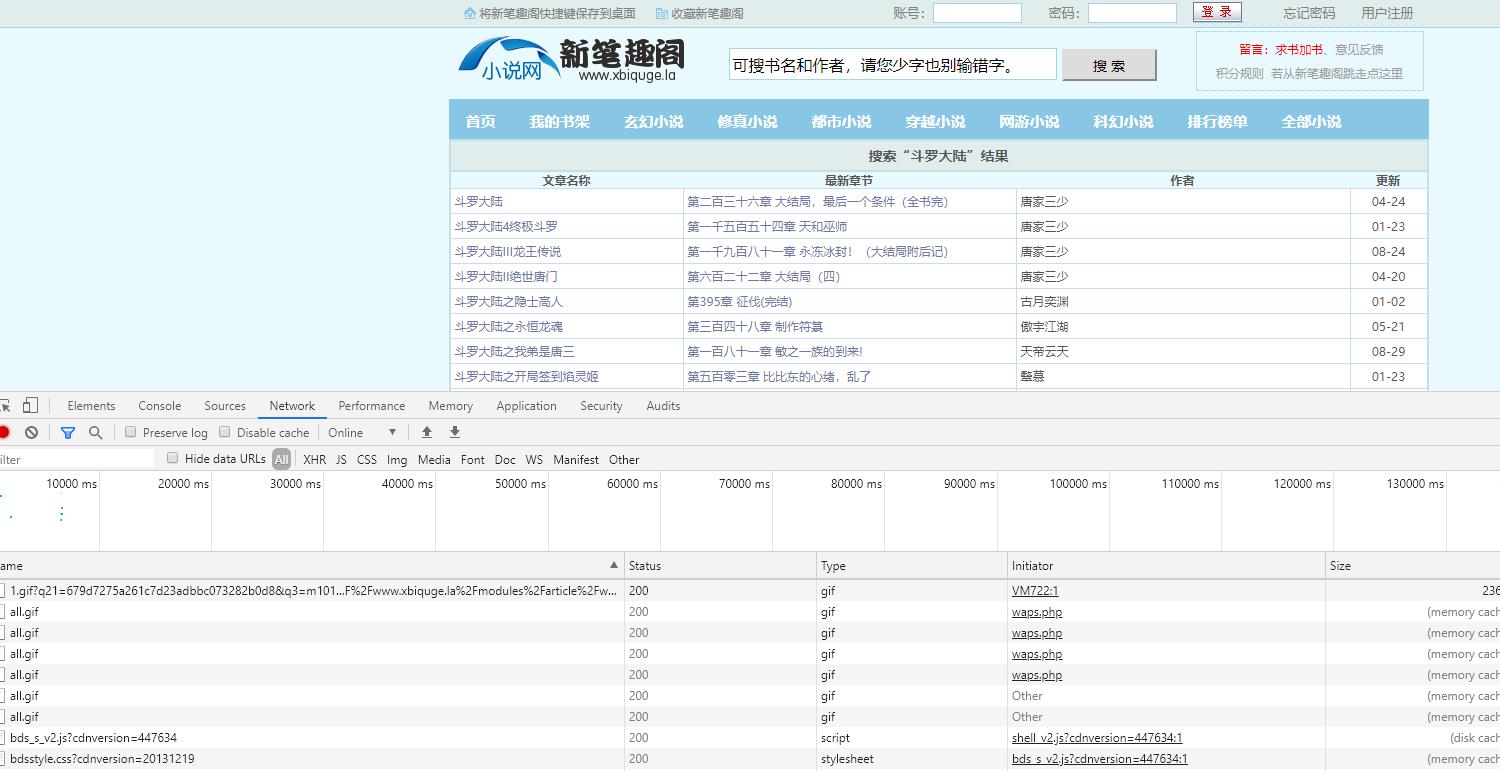
4、找到获取小说信息的请求
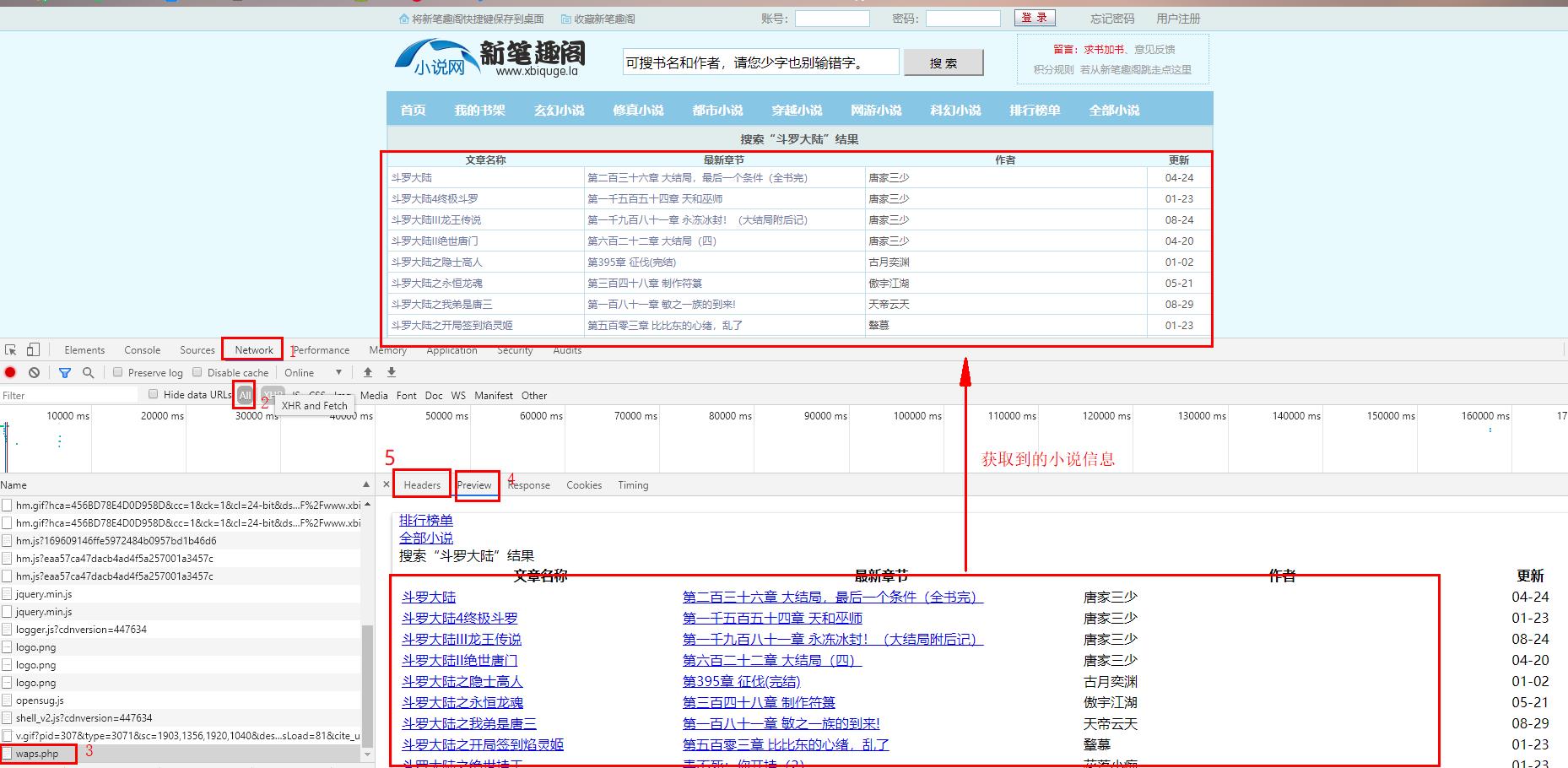
5、点击上图的第五步,找到数据的请求地址和请求数据,获取到请求方式(post)
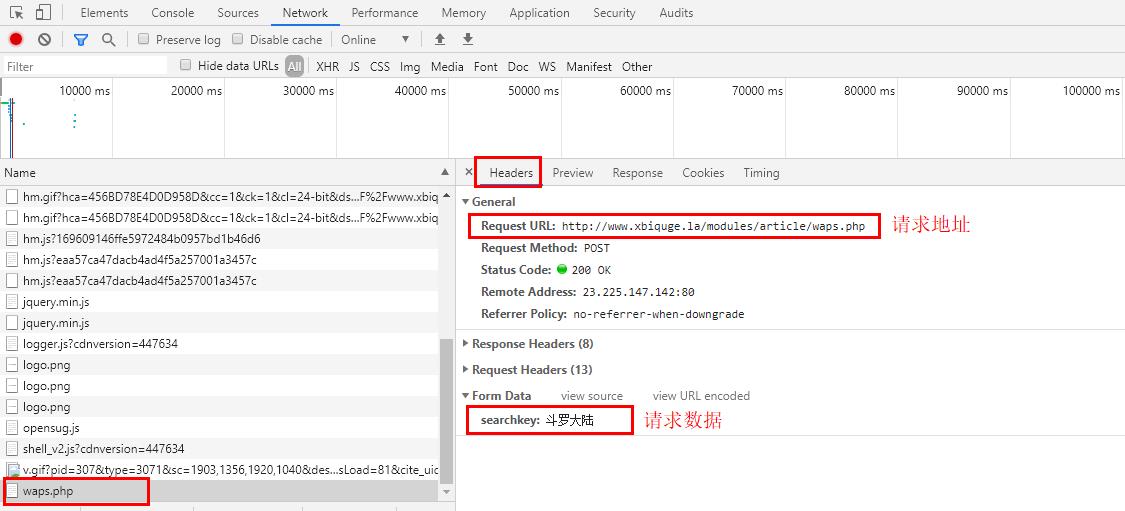
由此可以看出,每次请求的都是同一个地址,根据每次请求的不同
“searchkey”数据,来区别每次请求的数据
使用requests网络请求模块
pip install requsts # 模块安装
代码实现
search_url = "http://www.xbiquge.la/modules/article/waps.php"
data = {
'searchkey': "斗罗大陆"
}
res = requests.post(search_url, data) # 进行post请求
res.encoding = 'utf-8'
print(res.text)
html = etree.HTML(res.text) # <Element html at 0x7ff3fe0d6108>
print(html)
6、分析获取到的数据,找到小说存放地址
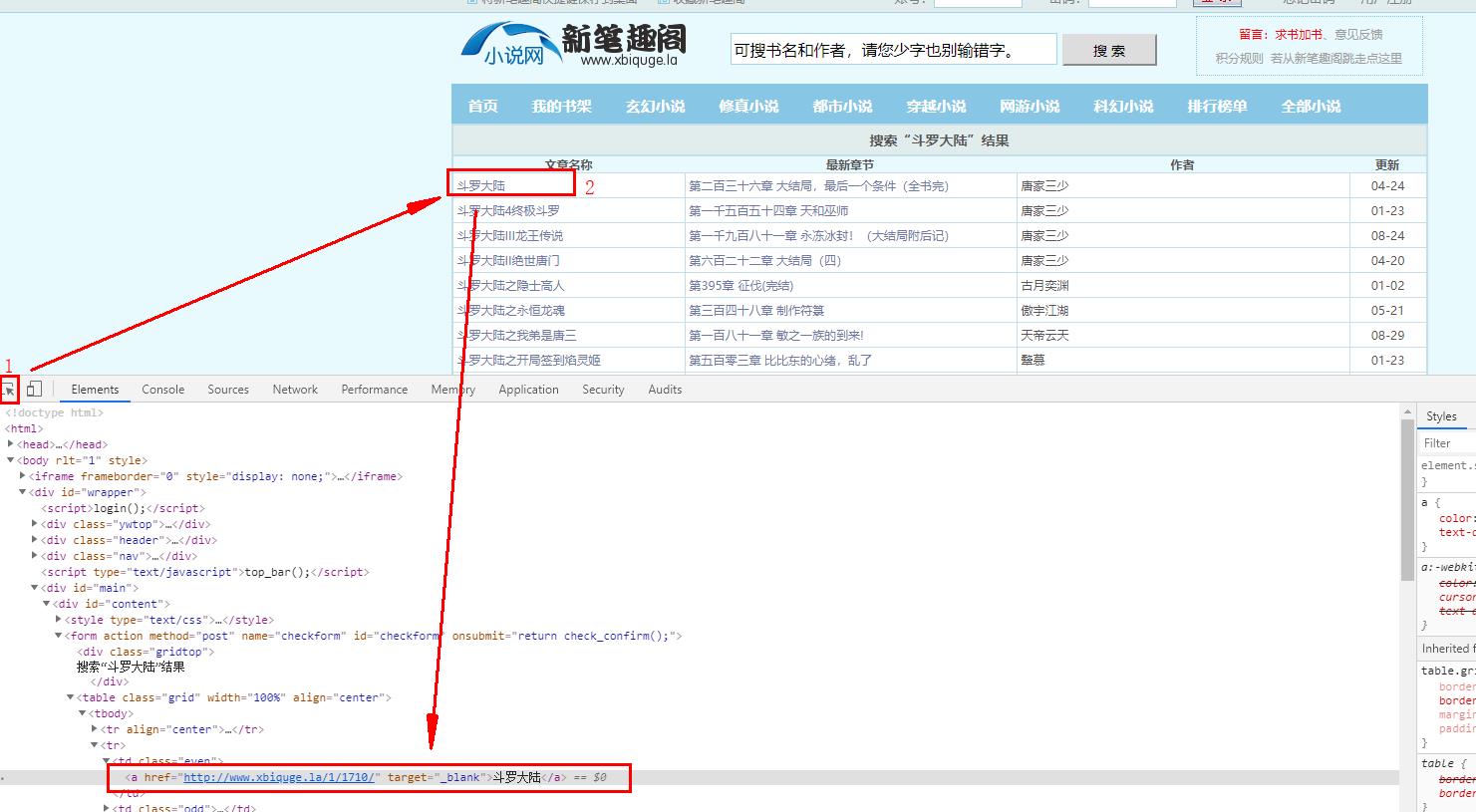
7、找到关键数据,小说地址、小说名称、作者
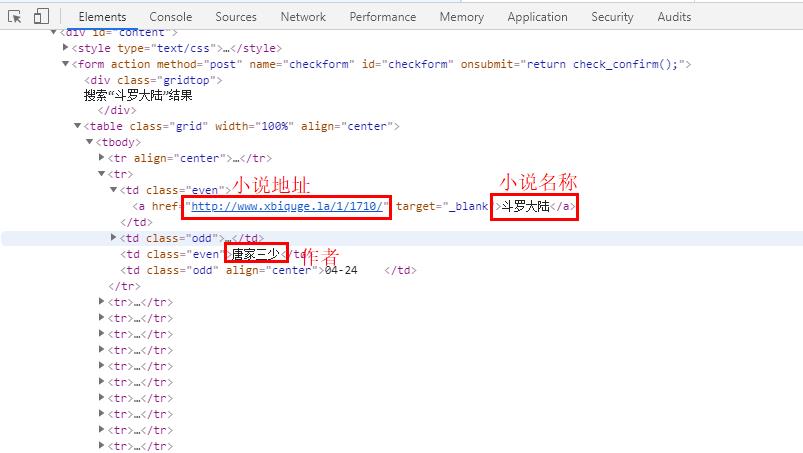
代码实现(接第5步代码)
book_root = html.xpath("//*[@class='grid']")
# print(book_root)
# print(etree.tostring(book_root[0]))
book_list = book_root[0].xpath("./tr")
del book_list[0]
# print(book_list)
# print(etree.tostring(book_list[0]))
if len(book_list) == 0: # 搜索结果为空时
return []
book_url_list = book_list[0].xpath("./td/a/@href")[0]
# print(book_url_list)
book_message = book_list[0].xpath("./td/a/text()")
# print(book_message)
book_user_list = book_list[0].xpath("./td/text()")[1]
# print(book_user_list)
book_list_meesage = []
for item in book_list:
book_buf = {}
book_buf["book_name"] = item.xpath("./td/a/text()")[0]
book_buf["book_url"] = item.xpath("./td/a/@href")[0]
book_buf["book_user"] = item.xpath("./td/text()")[1]
book_buf["book_size"] = item.xpath("./td/a/text()")[1]
book_list_meesage.append(book_buf)
print(book_buf["book_name"], " : ", book_buf["book_user"], " : ", book_buf["book_size"])
print(book_buf["book_url"])
print("*********************************************")
8、进入该书列表,继续找到小说的请求
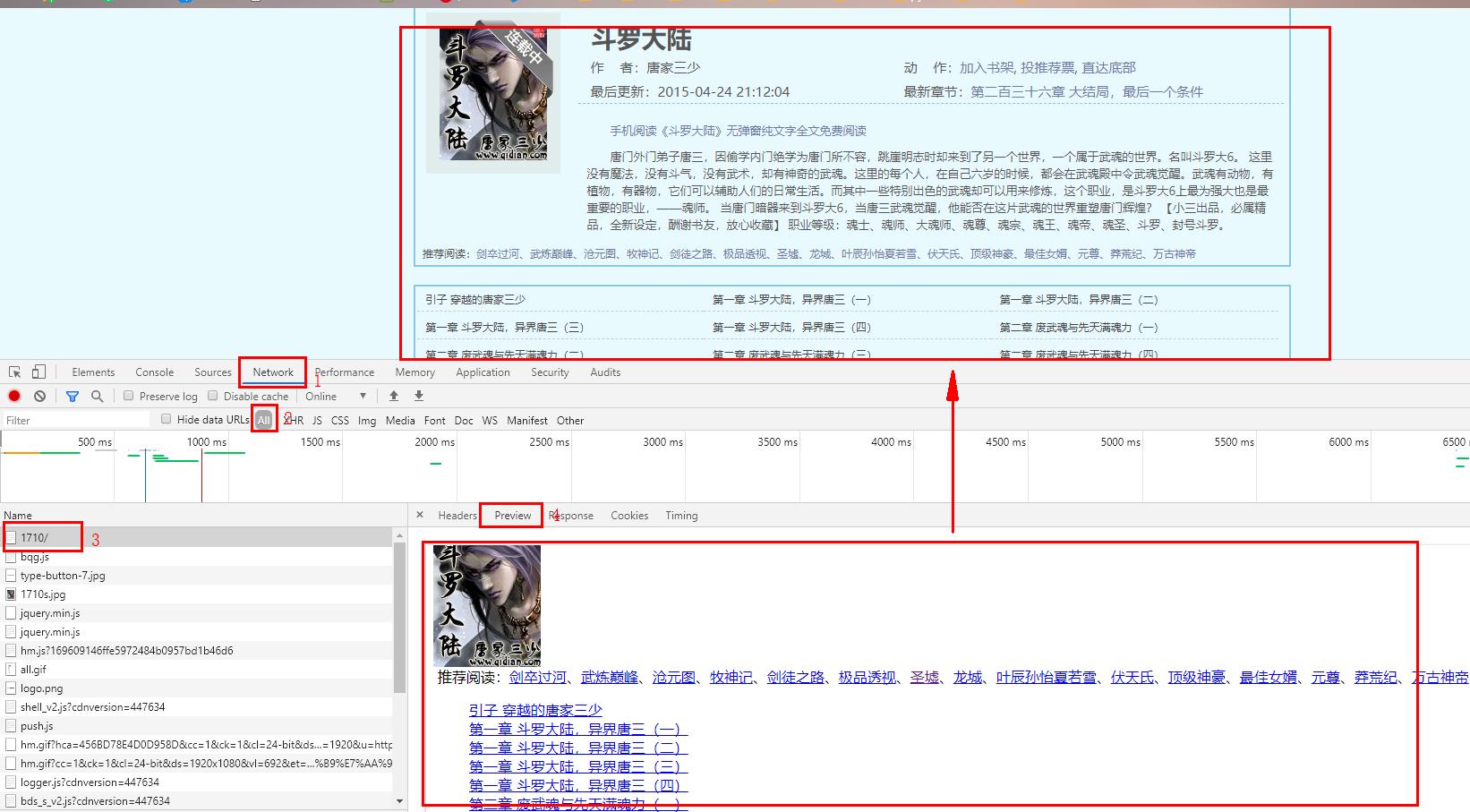
9、找到请求地址,获取请求方式(get)
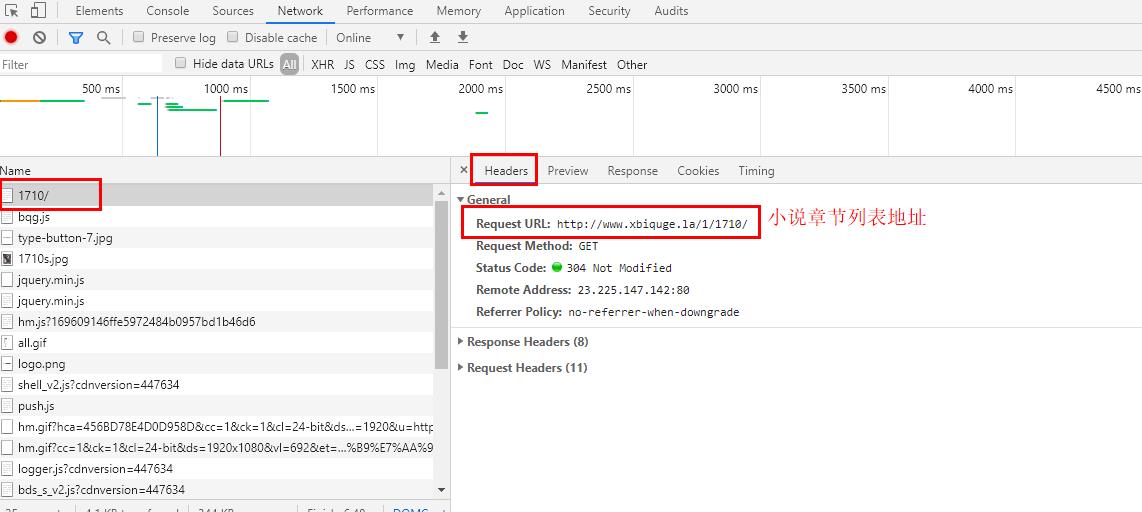
根据刚刚已经获得的小说列表地址,
代码实现
"""
:param url: 传入需要爬取的网站
:return: 响应体
"""
response = requests.get(url)
# 自动解决乱码问题
response.encoding = response.apparent_encoding
# 将网页数据结构化
sel = parsel.Selector(response.text)
print(response.text)
10、分析网页结构,找到章节地址
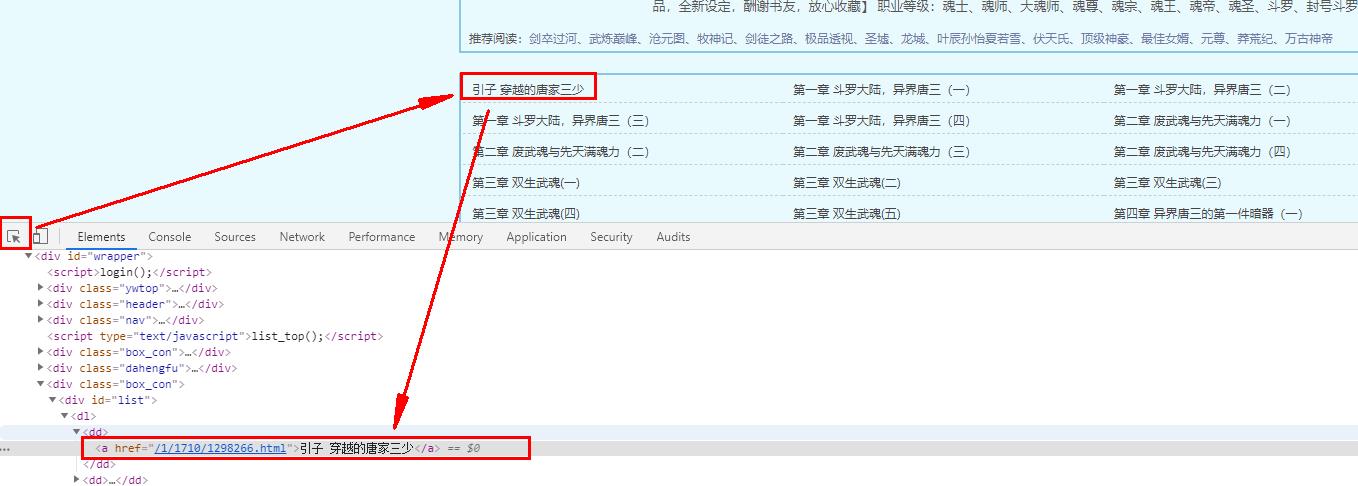
代码实现(接第9步代码)
# 提取出书名
book_name = sel.xpath('//div[@id="info"]/h1/text()').get()
# 根据xpath提取每个章节目录地址
index = sel.xpath('//*[@id="list"]/dl/dd').getall()
print(book_name)
url_list = []
for i in index:
# 得到的是章节地址的关键性数据,需要经过组合得到真正的地址
get_url = "http://www.xbiquge.la" + re.match(r'(.*)"(.*?)".*', i).group(2)
url_list.append(get_url)
print(get_url)
11、进入小说章节,找到获取数据的请求
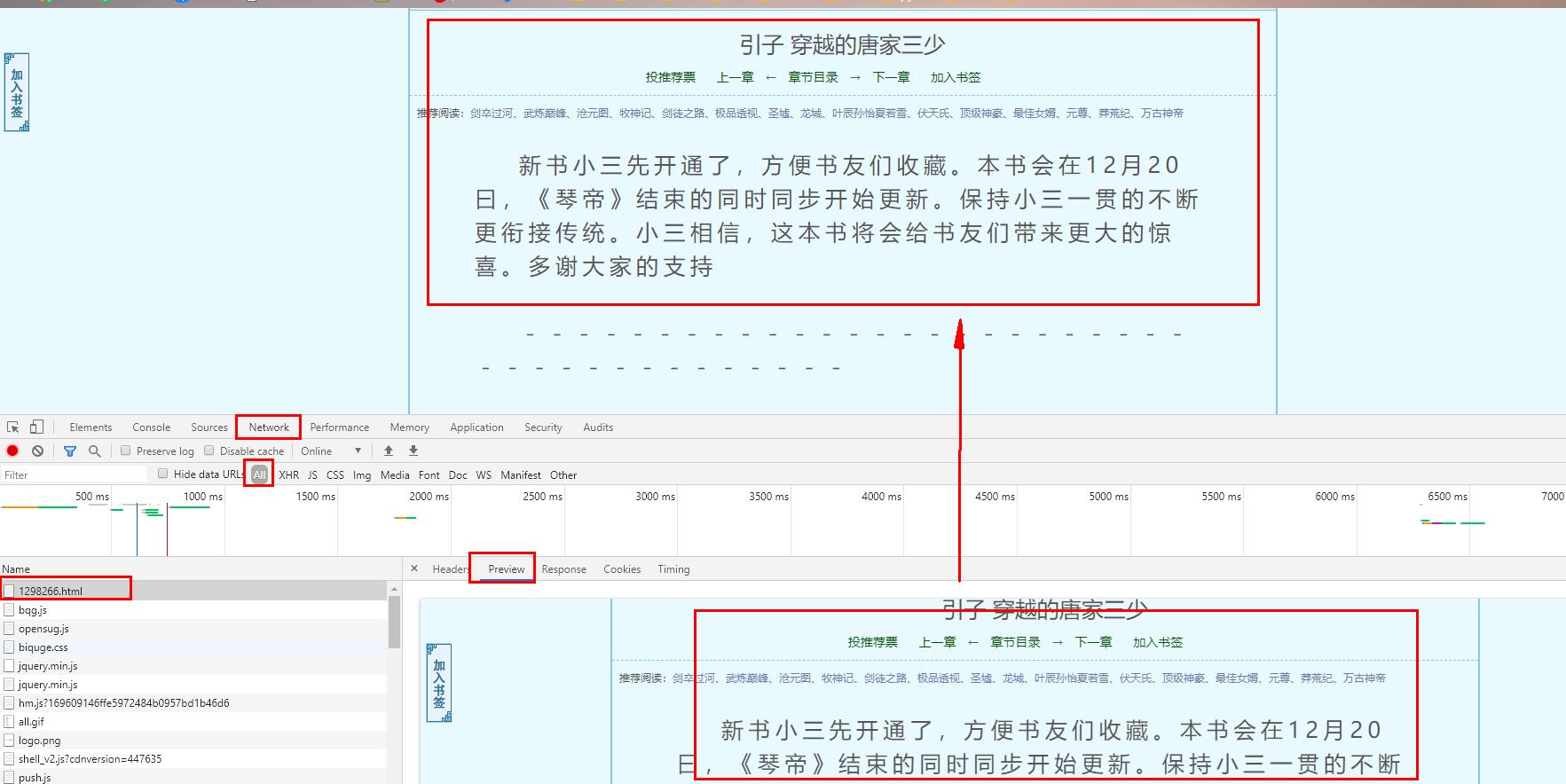
12、获取到请求方式(get)
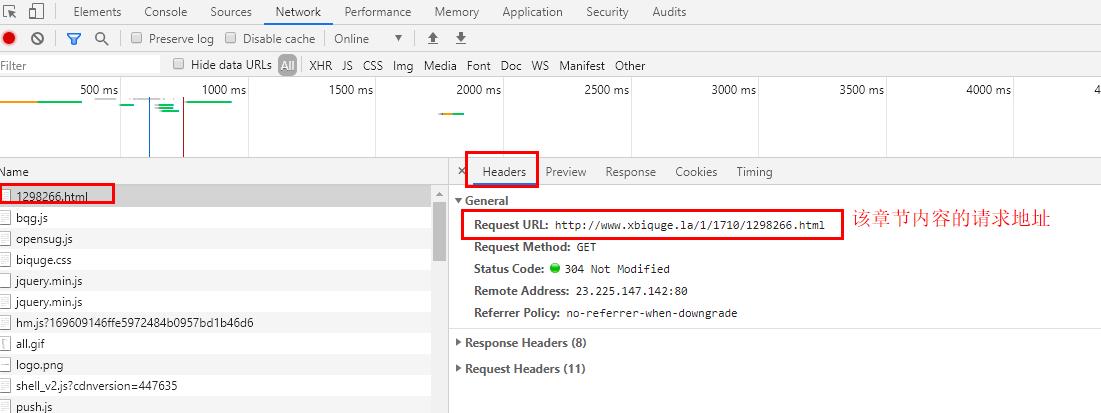
代码实现
"""
:param url:需要爬取这一章小说的地址
"""
response = requests.get(url)
#自动解决乱码问题
response.encoding = response.apparent_encoding
print(response.text)
# 将网页数据结构化
sel = parsel.Selector(response.text)
13、分析网页结构,获取小说内容
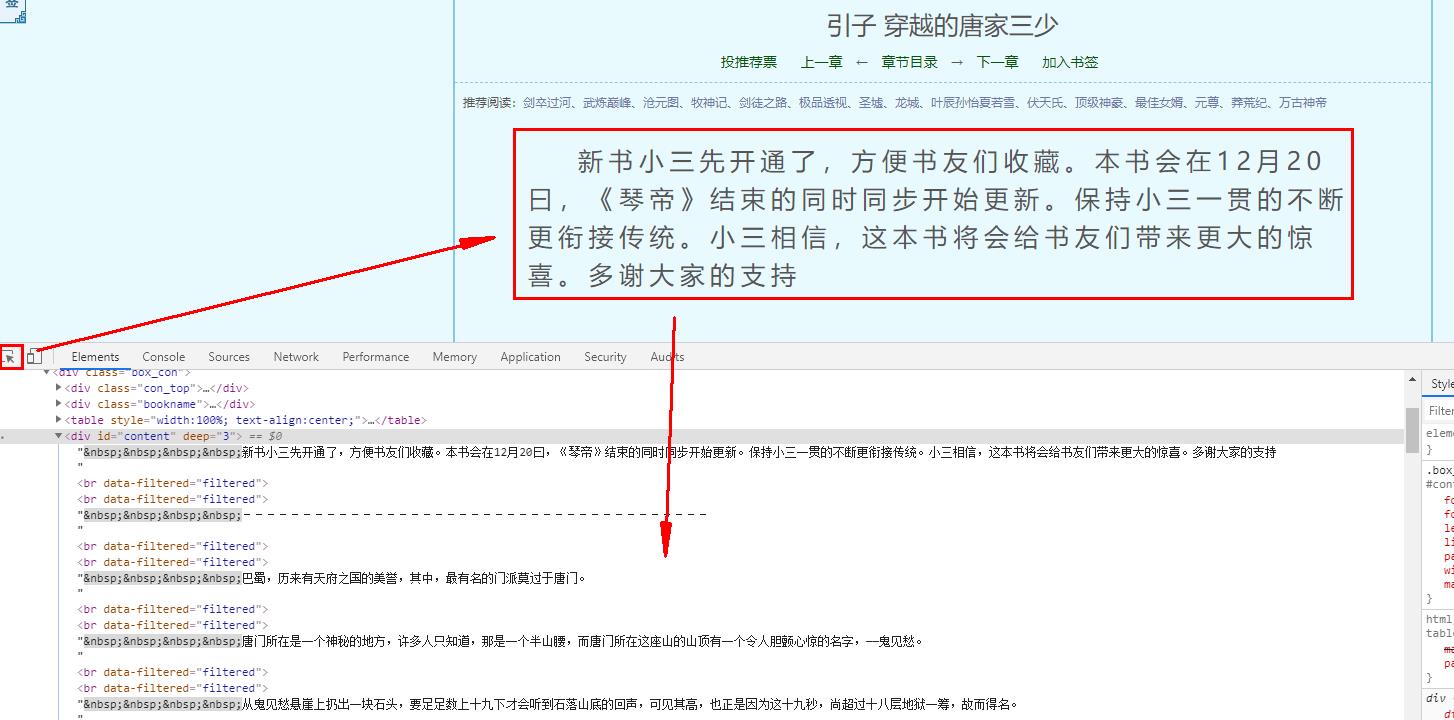
代码实现,接第12步代码
# 根据css选择器提取标题
chapter_title = sel.css('div.bookname > h1::text').get()
# 提取内容
content = sel.css('#content::text').getall()
chapter_data = []
# 去掉最后三行
for con in content:
print(con)
# str使用replace去除空格
chapter_data.append(con.replace('\xa0', ""))
三、总结
爬取过程:
- 在首页获取到搜索请求的地址
- 在搜索框中输入小说名
- 在搜索结果中,找到小说地址
- 在小说章节列表中获取每一章节的地址
- 在每一章节中爬取小说内容
该帖子主要是讲如何在小说平台上爬取小说内容的过程,具体实现请参考git上的代码,看代码前,请认真阅读redme文档
内容总结
以上是互联网集市为您收集整理的python爬取多网小说全部内容,希望文章能够帮你解决python爬取多网小说所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。