首页 / PYTHON / python爬取珞珈1号卫星数据
python爬取珞珈1号卫星数据
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了python爬取珞珈1号卫星数据,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含1497字,纯文字阅读大概需要3分钟。
内容图文

首先登录珞珈一号数据系统查询想要的数据
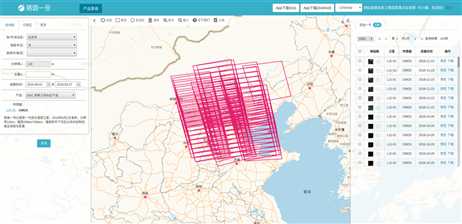
利用浏览器审查元素获取包含下载信息的源码
将最右侧的table相关的网页源码copy到剪切板备用
利用python下载数据
#
# utf-8
import
requests
import
os
#
import urllib.request
from bs4 import BeautifulSoup
from tqdm import tqdm
import pandas as pd
def saveFile(url,fileName):
# ‘‘‘ 保存文件‘‘‘
r = requests.get(url, stream=True)
chunkSize = 256
# print(‘dowloading...‘,fileName)
with open(‘data/‘+fileName, ‘wb‘) as f:
pbar = tqdm( unit="B", total=int( r.headers[‘Content-Length‘] ) ,desc = "downloading..."+fileName)
for chunk in r.iter_content(chunk_size=chunkSize):
if chunk: # filter out keep-alive new chunks pbar.update (len(chunk))
f.write(chunk)
html = ‘‘‘将table的源码粘贴到这里‘‘‘## get download url and file name
soup = BeautifulSoup(html)
tbody = soup.findAll(‘tbody‘)[0]
trs = tbody.findAll("tr")
data = []
for tr in trs:
tds = tr.findAll("td")[-4:]
temp = []
#for td in tds[:-1]:
temp.append(td.text)
a = tds[-1].findAll("a")[-1]
## download url
href = "http://59.175.109.173:8888" + a["href"]
temp.append(href)
data.append(temp)
dataSet = pd.DataFrame(data,columns = ["weixing","chuanganqi","time","url"])
###file name
dataSet.loc[:,"fileName"] = dataSet.loc[:,"weixing"] + dataSet.loc[:,"chuanganqi"] + dataSet.loc[:,"time"] + "-" + dataSet.index.map(str) + ".tar.gz"#### dowloadfor i in tqdm(range(dataSet.shape[0])):
# if i<start:# continue# if i > 200:# continue
row = dataSet.loc[i,:]
fileName = row["fileName"]
url = row["url"]
saveFile(url,fileName)
原文:https://www.cnblogs.com/wybert/p/10613873.html
内容总结
以上是互联网集市为您收集整理的python爬取珞珈1号卫星数据全部内容,希望文章能够帮你解决python爬取珞珈1号卫星数据所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。
来源:【匿名】