from zhihu_oauth import ZhihuClient
from zhihu_oauth.exception import NeedCaptchaExceptionclient = ZhihuClient()try:client.login(‘email_or_phone‘, ‘password‘)print(u"登陆成功!")
except NeedCaptchaException:# 保存验证码并提示输入,重新登录with open(‘a.gif‘, ‘wb‘) as f:f.write(client.get_captcha())captcha = input(‘please input captcha:‘)client.login(‘+8613872273541‘, ‘z289784552‘, capt...
用PHP写了一个网页,可以获取百度百科词条:http://www.selflink.cn/xiaobaike(只爬取摘要部分) 那么通过Python来爬取,只需要不断向这个网页POST数据,获取返回值就可以了。由于是我自己的网页,保存返回值我也让PHP在服务器端来完成了,所以Python的任务只需要不断向服务器POST数据。 那么POST什么数据呢?暂时找到了一个名词大全的网页。http://cidian.911cha.com/cixing_mingci.html足足20页的名词,足够作为名词POST数据的来...
日期:2020.01.27博客期:135星期一 【本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)】 今天问了一下老师,信息领域热词从哪里爬,老师说是IT方面的新闻,嗯~有点儿意思了! 我找到了好多IT网站,但是大多数广告又多,名词也不专一针对信息领域,所以啊我就暂且用例一个相对还好的例子: 数据来源网址:https://news.51cto.com/(最终不一定使用此网站的爬取数据) 网站的相关热词来源...
在有道翻译页面中打开开发者工具,在Headers板块找到Request URL以及相应的data。 import urllib.request
import urllib.parse
import jsoncontent=input(‘请输入需要翻译的内容:‘)#_o要去掉,否则会出先error_code:50的报错
url=‘http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule‘data={}
#开发者工具里有,i和doctype键不可少
data[‘i‘]=content
data[‘from‘]=‘AUTO‘
data[‘to‘]=‘AUTO‘
data...
安装环境:pip install requests
pip install lxml
pip install fire使用命令:python fofa.py -s=title="你的关键字" -o="结果输出文件" -c="你的cookie"
代码如下:import requests,time,base64,fire
from lxml import etree
def fofasc(s,o,c):try:sbase64 = (base64.b64encode(s.encode(‘utf-8‘))).decode(‘utf-8‘)cookies = {"_fofapro_ars_session": c}headers = {‘User-Agent‘: ‘Mozilla/5.0 (Linux; Android 7.1.2;...
# -*- coding: utf-8 -*-import urllib.request
import json#定义要爬取的微博大V的微博ID
id=‘3924739974‘#设置代理IP
proxy_addr="122.241.72.191:808"#定义页面打开函数
def use_proxy(url,proxy_addr):req=urllib.request.Request(url)req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0")proxy=urllib.reque...
首先登录珞珈一号数据系统查询想要的数据 利用浏览器审查元素获取包含下载信息的源码将最右侧的table相关的网页源码copy到剪切板备用利用python下载数据 ## utf-8import requests
import os
# import urllib.requestfrom bs4 import BeautifulSoup
from tqdm import tqdm
import pandas as pd def saveFile(url,fileName):# ‘‘‘ 保存文件‘‘‘r = requests.get(url, stream=True)chunkSize = 256# print(‘dowloading...‘,fi...
用了一周的时间总算搞定了,跨过了各种坑,总算调试成功了,记录如下:1、首先在cmd中用命令行建立douban爬虫项目scrapy startproject douban2、我用的是pycharm,导入项目后,1)在items.py中定义爬取的字段items.py代码如下:123456789101112# -*- coding: utf-8 -*-import scrapy class DoubanBookItem(scrapy.Item): name = scrapy.Field() # 书名 price = scrapy.Field() # 价格 edition_year...
#encoding:UTF-8import urllib.parseimport urllib.requestimport base64import reimport sysimport timefrom random import sampleimport codecsfrom html.parser import HTMLParserlog = ‘gogogo.txt‘logfile = codecs.open(log,‘w‘,‘utf-8‘)class MyHTMLParser(HTMLParser): def __init__(self): HTMLParser.__init__(self) self.a=0 self.span=0; def handle_starttag(self,tag,attrs): ...
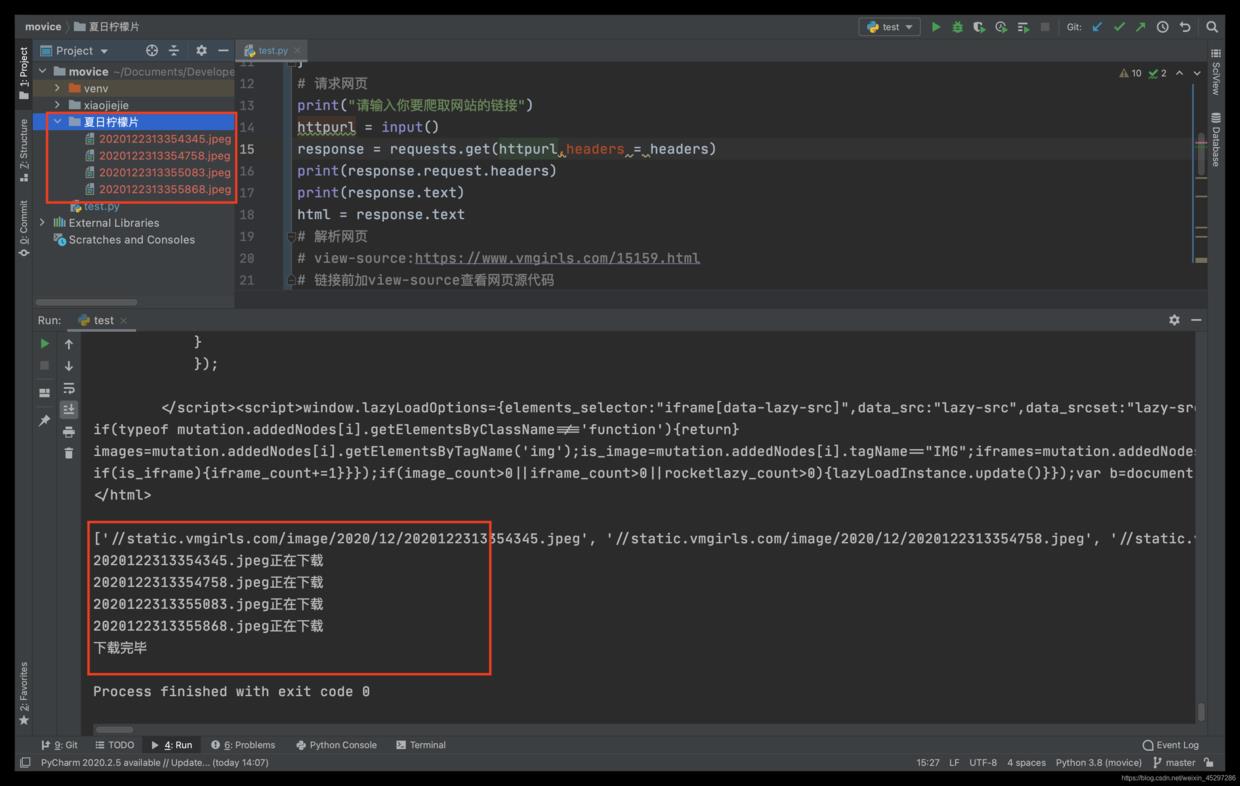
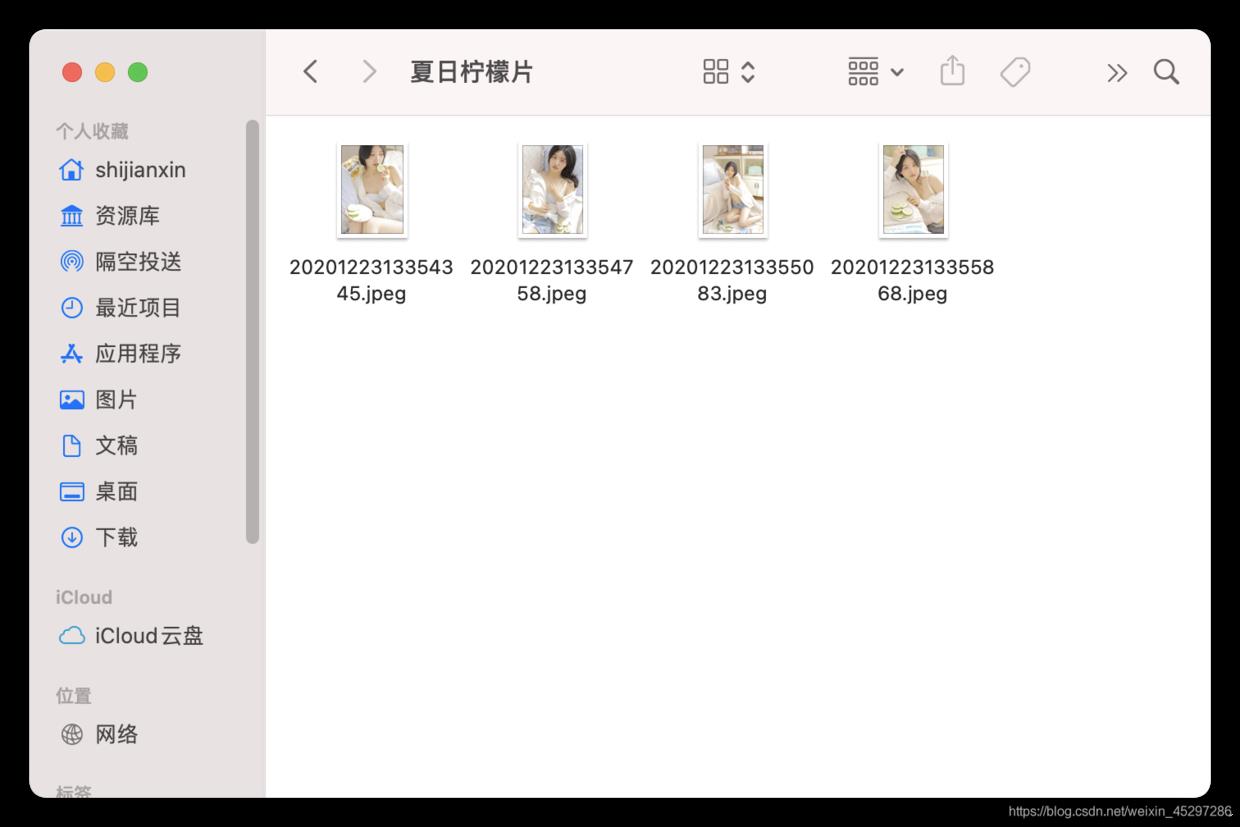
学了两天python,语法慢慢熟悉吧,数据结构都没写过。写了一个爬图片的小东西。挺有意思的。都是女神照 (????)用的是正则表达式, 1‘‘‘ 2符号:3 . 匹配任意字符,\n除外4 * 匹配前一个字符一次或无限次5 ? 匹配前一个字符0次或1次6 .* 贪心匹配7 .*? 非贪心匹配8 () 返回括号内容9方法:
10 findall
11 search
12 sub
1314用的最多的是(.*?)
15‘‘‘requests的导入,我也是醉了,还要eas...
前言本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。作者:菜鸟级程序猿 代码实现import requests
from lxml import etree
import time
import random
import pandas as pd
import json
from sqlalchemy import create_engine
from sqlalchemy.dialects.oracle import DATE,FLOAT,NUMBER,VARCHAR2
import cx_Oracle 先导入需要用的包PS:如有需要Python学...
#coding=utf-8import datetime
import time
import sys
import os import urllib2
import urllibsx = ‘小说站网址‘type = sys.getfilesystemencoding()
user_agent = ‘Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)‘
headers = { ‘User-Agent‘ : user_agent } fo = open("note.txt", "wb")def getHtml(url): try: request = urllib2.Request(url, headers=headers) response = urllib2.urlopen(request) data = ...
1#html文本提取 2from bs4 import BeautifulSoup3 html_sample = ‘ 4<html> 5<body> 6<h1 id = "title">Hello world</h1> 7<a href = "#www.baidu.com" class = "link"> This is link1</a> 8<a href = "#link2" class = "link"> This is link2</a> 9</body> 10</html>‘11 soup = BeautifulSoup(html_sample,‘html.parser‘)
12print(soup.text)
13 soup.select(‘h1‘)
14print(soup.select(‘h1‘)[0].text)
15print(soup.s...
import requestsimport reimport os,syslinks=[]titles=[]headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36"}def get_url(page): url=‘http://www.zbjuran.com/mei/xinggan/list_13_%s.html‘%(page) data=requests.get(url,headers=headers).text data_use=re.findall(‘<div class="name"><a target="_bla...
简介抖音,是一款可以拍短视频的音乐创意短视频社交软件,该软件于2016年9月上线,是一个专注年轻人的15秒音乐短视频社区。用户可以通过这款软件选择歌曲,拍摄15秒的音乐短视频,形成自己的作品。此APP已在Android各大应用商店和APP Store均有上线。今天咱们就用Python爬取抖音视频准备:环境:Python3.6+WindowsIDE:你开行就好,喜欢用哪个就用哪个模块:1from splinter.driver.webdriver.chrome import Options, Chrome
2from ...