一,JNI java 调c++动态库函数的问题 1.多参数回传 2.参数传递出现乱码 二,解决 1.使用byte[]数组传入c++,在生成的头文件里就会变成jbyteArray 类型 例如,java 中参数:byte[]account,头文件里参数变成jbyteArray account, 通过c++修改完account的值后,java要获取该值,直接使用 jbyte* jbAccount = (env)->GetByteArrayElements(env, account, 0); char* szAccount = (char*)jbAccount; 指针的地址并不是account的地址,最后赋...
中文字在C/C++中的处理 现在编程的语言和编程环境随着中国的发展開始对中文有进一步的支持。可是对中文的支持整体来说是有缺陷的,并且有与编译环境的不同导致中文在当前的C/C++中有非常多问题,并且非常多版本号对中文的支持是不全然的。就拿DEV-C++和VS2005为例。对与MSDN的帮助和网上的讲述两者在那些代码的支持有非常多不同的地方。 而我要讨论的就是对于中文在C/C++的应用方法。首先中文字是在一般char的范围以外...
//utf8Str:以字节(char*或者Byte*)读取中文的字符串(乱码)
CString UTF8toUnicode(constchar* utf8Str)
{UINT theLength=strlen(utf8Str);return UTF8toUnicode(utf8Str,theLength);
}CString UTF8toUnicode(constchar* utf8Str,UINT length)
{CString unicodeStr;unicodeStr=_T("");if (!utf8Str)return unicodeStr;if (length==0)return unicodeStr;WCHAR chr=0;//一个中文字符for (UINT i=0;i<length;){//UTF8的三种中文格...
把页面编码转换为UTP-8的编码1.打开G:\vs2013way\VC\vcprojectitems目录在file.hnewc++file.cpp中写两句话#pragma once#pragma execution_character_set("utf-8")这个的作用是每次新建一个.h或者.cpp文件的时候,会自动先帮我们写好这两个话 2.文件-高级保存选项-设置为UTF-8的无签名的编码格式,注意,每个文件都要设置 上诉的方法在cocos2d-x中没有用,还是会出现中文乱码,而且在自己写C++代码的时候,虽然帮我们写好了那两句话...
加上下面一句即可:mysql_query(&mysql,"set names utf8"); 此处的utf8必须要和在数据库中执行SQL语句:show variables like ‘character_set_%‘状态表中的编码一致!我的编码如下所示:只需要一致即可,此处需要注意的是utf8兼容性更好!!!推荐使用utf8编码!!!备注:此文希望给大家提供帮助!都是经过我的实践总结!!!Linux环境下MySQL数据库用C/C++语言插入中文数据元组显示乱码问题标签:rac 乱码问题 ima 需要 ...
bitsCN.com
关于mysql编码问题的设置:http://www.bitsCN.com/database/201108/101151.html 问题简述:环境:linuxmysql编码设置:终端插入中文,然后查看,不乱。phpmyadmin插入中文,然后查看,不乱。php连接 设置mysql_query("SET NAMES UTF8"),查看,由终端或phpmyadmin插入的都不乱。唯一乱的是c++写进去的中文,全变乱码了。解决:c++里面数据库连接完了,加上还不行,为啥呢?右键清空项目,再重新编译执行,不乱码了。所以...
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <windows.h>using namespace std;string UTF8ToGB(const char* str)
{string result;WCHAR *strSrc;LPSTR szRes;//获得临时变量的大小int i = MultiByteToWideChar(CP_UTF8, 0, str, -1, NULL, 0);strSrc = new WCHAR[i + 1];MultiByteToWideChar(CP_UTF8, 0, str, -1, strSrc, i);//获得临时变量的大小i = WideCharToMultiByte(CP_ACP, 0, ...
前几天在一篇文章中看见一段用大括号包裹的C++代码(大概长下面这样)
{//一些必要的预处理代码...吧啦吧啦吧啦...int main(){//代码主体...吧啦吧啦吧啦...}}
当时我一脸懵逼,这是神马语法,能通过编译?于是乎我把这段代码COPY进了我的Dev编译器,Amazing!居然 编译顺利过,运行也没出错!我突发奇想,如果能在代码中放一段乱码 还不出错 岂不是一件很装逼的事,于是便有了下面这段代码
#include<iostream>using namespace st...
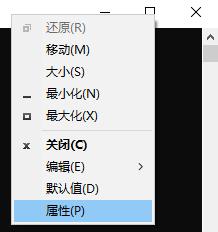
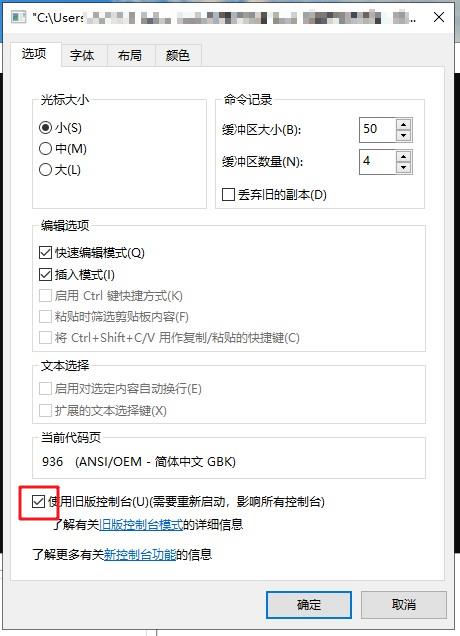
问题:cout输出中文乱码。例如下面的代码输出会乱码。cout << "成功!" << endl;输出结果: 解决方案: 控制台还原旧版即可,打开程序->右键->属性->使用旧版控制台->重启程序->解决!
乱码的根本原因就是字符串编码的方式也字符串解码方式不一致导致的, 而在我们平常用的编码编码方式一般都是utf-8以gbk之间的相互转换, 下面给出编码方式的转换代码string UtfToString(string strValue){int nwLen = ::MultiByteToWideChar(CP_ACP, 0, strValue.c_str(), -1, NULL, 0);wchar_t * pwBuf = new wchar_t[nwLen + 1];//加上末尾\0ZeroMemory(pwBuf, nwLen * 2 + 2);::MultiByteToWideChar(CP_ACP, 0, strValue.c_str(),...