首页 / 算法 / 《算法图解》笔记(6) 狄克斯特拉算法
《算法图解》笔记(6) 狄克斯特拉算法
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了《算法图解》笔记(6) 狄克斯特拉算法,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3701字,纯文字阅读大概需要6分钟。
内容图文
 狄克斯特拉算法")
狄克斯特拉算法(Dijkstra’s algorithm)
狄克斯特拉算法用于每条边都有关联数字的图,这些数字称为权重(weight)。带权重的图称为加权图(weighted graph),不带权重的图称为非加权图(unweighted graph)。要计算非加权图中的最短路径,可使用广度优先搜索。要计算加权图中的最短路径,可使用狄克斯特拉算法。
狄克斯特拉算法包含4个步骤:
- 找出最便宜的节点,即可在最短时间内前往的节点。
- 对于该节点的邻居,检查是否有前往它们的更短路径,如果有,就更新其开销。
- 重复这个过程,直到对图中的每个节点都这样做了。
- 计算最终路径。
无向图是两个节点彼此指向对方,也就是环。在无向图中,每条边都是一个环。狄克斯特拉算法只适用于有向无环图(directed acyclicgraph,DAG)。
算法实现
下面来看看如何使用代码来实现狄克斯特拉算法,这里以下面的图为例。
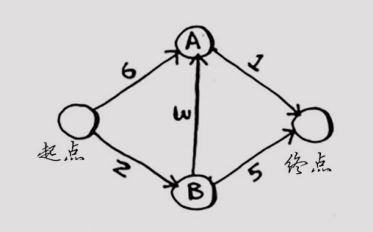
要编写解决这个问题的代码,需要三个散列表。示例代码如下:
graph = {}
graph["start"] = {}
graph["start"]["a"] = 6
graph["start"]["b"] = 2
'''
print(graph["start"].keys())
print (graph["start"]["a"])
print (graph["start"]["b"])
'''
graph["a"] = {}
graph["a"]["fin"] = 1
graph["b"] = {}
graph["b"]["a"] = 3
graph["b"]["fin"] = 5
graph["fin"] = {}
#表示无穷大
infinity = float("inf")
#开销散列表
costs = {}
costs["a"] = 6
costs["b"] = 2
costs["fin"] = infinity
#父节点散列表
parents = {}
parents["a"] = "start"
parents["b"] = "start"
parents["fin"] = None
#记录处理过的节点 这里是方括号
processed = []
def find_lowest_cost_node(costs):
lowest_cost = float("inf")
lowest_cost_node = None
for node in costs:
cost = costs[node]
if cost < lowest_cost and node not in processed:
lowest_cost = cost
lowest_cost_node = node
return lowest_cost_node
node = find_lowest_cost_node(costs)
while node is not None:
cost = costs[node]
neighbors = graph[node]
for n in neighbors.keys():
new_cost = cost +neighbors[n]
if costs[n] > new_cost:
costs[n] = new_cost
parents[n] = node
processed.append(node)
node = find_lowest_cost_node(costs)
#通过list将字典中的keys和values转化为列表
#values = list(parents.values())
#无语啦processed[]就是给出的路线啊=。=
print("起点到终点最短路径的总权重是:"+str(costs["fin"]))
#print("最优路径是:start→"+str(processed[])+"→"+str(values[-2] )+"→终点")
print("起点到终点最短路径的总权重是:%s"%(costs["fin"]))
#%s字符串 %d整型数据
#print("xxx", end=' ')指定属性不换行
# 打印最优路径
print("最优路径是:start",end='')
for i in processed:
print("→%s"%i, end='')
小结
- 广度优先搜索用于在非加权图中查找最短路径。
- 狄克斯特拉算法用于在加权图中查找最短路径。
- 仅当权重为正时狄克斯特拉算法才管用。
- 如果图中包含负权边,请使用贝尔曼-福德算法。
小贴士
Array:它是数组,申明数组的时候就要初始化并确定长度,长度不可变,而且它只能存储同一类型的数据,比如申明为String类型的数组,那么它只能存储S听类型数据 。
ArrayList:它是一个集合,需要先申明,然后再添加数据,长度是根据内容的多少而改变的,ArrayList可以存放不同类型的数据,,但不能存放基本类型数据,在存储基本类型数据的时候要使用基本数据类型的包装类。
当能确定长度并且数据类型一致的时候就可以用数组,其他时候使用ArrayList。
Python 字典(Dictionary) keys() 函数以列表返回一个字典所有的键。示例:
costs = {}
costs["a"] = 6
costs["b"] = 2
costs["fin"] = 5
for i in costs.keys():
print(i,costs[i])
keys = list(costs.keys())
values = list(costs.values())
print(values)
print(values[0])
print(values[-1])
程序时候用 + 拼接的时候忘记变量类型要一致,或者用第二种模式
例子:
print("起点到终点最短路径的总权重是:"+str(costs["fin"]))
print("起点到终点最短路径的总权重是:%s"%(costs["fin"]))
%d,%c,%s,%x是程序汇编语言中的格式符,它们的含义:
1、%d表示按整型数据的实际长度输出数据。
2、%c用来输出一个字符。
3、%s用来输出一个字符串。
4、%x表示以十六进制数形式输出整数。
实现print不换行
那如何我们不想换行,且不想讲输出内容用一个print函数输出时,就需要改变print默认换行的属性,
方法如下:
print('contents', end='!@#$%^&*')
end就表示print将如何结束,默认为end="\n"(换行)
栗子:
print("祝各位身体健康")
print("!")
print("祝各位身体健康", end=' ')
print("!")
内容总结
以上是互联网集市为您收集整理的《算法图解》笔记(6) 狄克斯特拉算法全部内容,希望文章能够帮你解决《算法图解》笔记(6) 狄克斯特拉算法所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。