首页 / 算法 / 机器学习算法-逻辑回归
机器学习算法-逻辑回归
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了机器学习算法-逻辑回归,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2798字,纯文字阅读大概需要4分钟。
内容图文

机器学习算法-逻辑回归
一. 逻辑回归模型
1.1 逻辑回归定义
LR 是一种简单、高效的常用分类模型,能处理二分类或者多分类。
1.2 逻辑回归模型
sigmoid 函数:
对线性回归的结果做一个在函数g上的转换,可以变化为逻辑回归,这个函数g在逻辑回归中我们一般取为sigmoid函数,形式如下:
g(z)=1+e?z1?
另外 这个函数有两个很好的特性:
(1)z 趋于正无穷时,g(z)->1, z 趋于负无穷时, g(z) ->0; 在二维坐标中展现成:
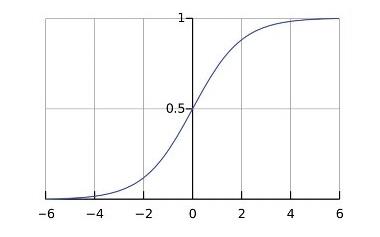
(2)g′(z)=g(z)(1?g(z))
== 逻辑回归一般模型:==
如果我们令g(z)中的z为:z=xθ,这样就得到了二元逻辑回归模型的一般形式:
h(xθ)=1+e?xθ1?
其中x为样本输入,hθ(x)为模型输出,可以理解为某一分类的概率大小。而θ为分类模型的要求出的模型参数。对于模型输出hθ(x),我们让它和我们的二元样本输出y(假设为0和1)有这样的对应关系,如果hθ(x)>0.5 ,即xθ>0, 则y为1。如果hθ(x)<0.5,即xθ<0,
二. 代价函数求解
2.1 定义代价函数的方法
由于线性回归是连续的,所以可以使用模型误差的的平方和来定义损失函数,但是逻辑回归不是连续的,自然线性回归损失函数定义的经验就用不上了。不过我们可以用最大似然法来推导出我们的损失函数:
(1) y 的概率分布函数表达式:
P(y=1∣x,θ)=hθ?(x)
P(y=0∣x,θ)=1?hθ?(x)
(2) 根据概率分布函数,我们就可以用似然函数最大化来求解我们需要的模型系数θ; 使得给定的输入x, 输出的y 的概率最大。最大似然函数:
L(θ)=i=1∏m?(hθ?(x(i)))y(i)(1?hθ?(x(i)))1?y(i)
(3) 代价函数表达式:
J(θ)=?m1?i=1∑m?(y(i)log(hθ?(x(i))))+(1?y(i))log(1?hθ?(x(i)))
2.2 代价函数求解方法-梯度下降

三. Sklearn 参数说明
详细参数说明
这里对 OVO,OVR ,MVM 进行补充说明:
OVR 是将一个类的样例作为正例,所有其他类的样例作为返利来训练N个分类器。在测试的时候弱仅有一个分类器预测为正类,则对应的类别标记作为最终分类结果,如果有多个分类器预测为正类,通常考虑各个分类器的置信度。
OvR相对简单,但分类效果相对略差(这里指大多数样本分布情况,某些样本分布下OvR可能更好)。而MvM分类相对精确,但是分类速度没有OvR快
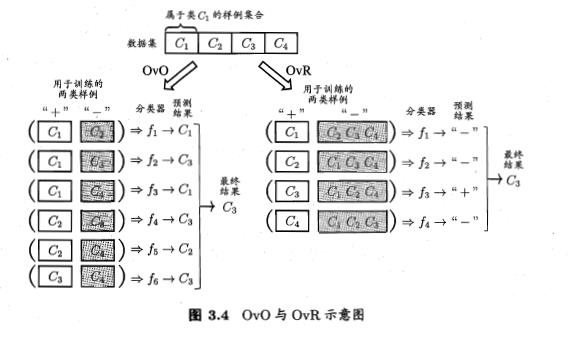
四. 常见问题
- 逻辑回归的优缺点?
优点:
1.模型的可解释性强,可以通过参数值看到特征对结果的影响
2.既可以得到分类结果也可以得到类别的概率值
3. 方便调整输出结果,通过调整阈值的方式
缺点:
1.模型的准确性不高
2.数据不平衡时,对正负样本的区分能力差 - 逻辑回归中的假设?
(1)数据服从伯努利分布。
(2)假设样本为正的概率 p 为一个 Sigmoid 函数。
参考
1.吴恩达机器学习
2.逻辑回归
3.线性回归和逻辑回归的整理
4.李烨-机器学习极简入门课
内容总结
以上是互联网集市为您收集整理的机器学习算法-逻辑回归全部内容,希望文章能够帮你解决机器学习算法-逻辑回归所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。